2022년 제4회 기출문제
2022년 4월 9일에 시행된 빅데이터 분석기사 필기 4회 기출문제입니다. 총 80문항이며 100점을 만점으로 하여 과목당 40점 이상, 전 과목 평균 60점 이상이면 합격입니다. 실제 시험과 100%일치하지는 않습니다. 정답 버튼을 클릭하시면 정답을 보실 수 있고 에러사항이 있으면 댓글을 달아 주시면 바로 수정하겠습니다.
[1과목 빅데이터의 이해]
1. HDFS에 대한 설명으로 옳은 것은?
① 복제의 횟수는 내부에서 결정된다.
② ETL, NTFA가 상위 프로그램이다.
③ GFS와 동일한 소스코드를 사용한다.
④ 네임노드는 저장공간에 네임노드 데이터를 같이 저장한다.
③ GFS와 동일한 소스코드를 사용한다.
2. 인공지능학습에 대한 설명으로 옳지 않은 것은?
① 훌륭한 알고리즘을 보유하였다면 학습을 생략해도 된다.
② 강인공지능은 범용으로 사용되기는 시기 상조이다.
③ 약인공지능의 제한된 기능을 뛰어넘어 더 발달된 인공지능이다.
④ 강인공지능이라고 불릴 만한 수준의 인공지능은 지금도 개발되지 않았다.
① 훌륭한 알고리즘을 보유하였다면 학습을 생략해도 된다.
3. 분산파일 시스템에 대한 설명으로 옳은 것은?
① 데이터베이스를 분산 저장한다.
② x86 서버의 CPU, RAM 등을 사용하므로 장비 증가에 따른 성능향상에 용이하다.
③ 여러 컴퓨터를 하나의 서버 환경에 저장한다.
④ 네트워크를 통한 여러 파일을 관리 및 저장하는 개념이다.
④ 네트워크를 통한 여러 파일을 관리 및 저장하는 개념이다.
4. 분석로드맵 설정시 우선순위 고려해야할 사항 아닌 것은?
① 비즈니스 성관 및 ROI
② 시급성
③ 분석 데이터 적용
④ 전략적 중요도
③ 분석 데이터 적용
5. 분석 시나리오 적용을 해야 하는 이유로 가장 적절하지 않은 것은?
① 이해관계자 도출
② 업무성과 판단
③ 최신 업무 형태 반영
④ 분석 목표 도출
③ 최신 업무 형태 반영
6. 빅데이터 분석기획 절차는?
① 프로젝트정의-> 범위설정 -> 위험계획수립 -> 수행계획수립
② 프로젝트정의-> 범위설정 -> 수행계획수립 -> 위험계획수립
③ 범위설정 -> 프로젝트정의 -> 수행계획수립 -> 위험계획수립
④ 범위설정 -> 프로젝트정의 -> 위험계획수립 -> 수행계획수립
③ 범위설정 -> 프로젝트정의 -> 수행계획수립 -> 위험계획수립
7. 개인정보 비동의 시에도 사용 가능한 경우가 아닌 것은?
① 법령상 의무를 준수하기 위하여 불가피한 경우
② 계약의 체결 및 이행을 위하여 불가피하게 필요한 경우
③ 정보주체 또는 제3자의 급박한 생명, 신체, 재산의 이익을 위하여 필요하다고 인정되는 경우
④ 개인 편의 제공 시 합당한 이유가 있으면 가능하다.
④ 개인 편의 제공 시 합당한 이유가 있으면 가능하다.
8. 개인정보 비식별화 기술에 대한 설명 중 가장 적절하지 않은 것은?
① 총계처리: 데이터의 총합 값으로 처리하여 개인 데이터의 값을 보이지 않도록 하는 기술
② 데이터 마스킹 : 개인식별에중요한 데이터 값을 삭제하는 기술
③ 가명처리: 개인 식별에 중요한 데이터를 식별할수 없는 다른 값으로 변경하는 기술
④ 범주화: 데이터의 값을 범주의 값으로 변환하여 값을 변경하는 기술
② 데이터 마스킹 : 개인식별에중요한 데이터 값을 삭제하는 기술
9. 가트너가 정의한 빅데이터 처리 플랫폼 특징 중 3V에 속하지 않는 것은?
① Value
② Volume
③ Velocity
④ Variety
① Value
10. 1제타바이트에 1byte의 아스키 코드를 넣으면 얼만큼 넣을 수 있는가?
① 2의 40승
② 2의 50승
③ 2의 60승
④ 2의 70승
④ 2의 70승
11. 다음 중 인메모리기반의 데이터 처리와 연관된 오픈소스 프로젝트는?
① 스파크
② 맵리듀스
③ 하이브
④ 피그
① 스파크
12. 다음 중 데이터분석 모델링과 관련하여 수행하는 업무가 아닌 것은?
① 데이터 분할
② 데이터 모델링
③ 프로젝트 성과 분석 및 평가 보고
④ 모델 적용 및 운영방안
③ 프로젝트 성과 분석 및 평가 보고
13. 다음 중 정형데이터와 비정형데이터와 관련된 것 중 옳은 것은?
① 동영상, 오디오 데이터는 정형 데이터에 속한다.
② 형태소는 정형데이터를 분석하기 위한 단위이다.
③ 정형데이터는 지정된 행과열에 의해 데이터의 속성이 구별되는 스프레드시트 형태의 데이터이다.
④ 비정형 데이터는 잠재적 가치가 가장 낮다.
③ 정형데이터는 지정된 행과열에 의해 데이터의 속성이 구별되는 스프레드시트 형태의 데이터이다.
14. 다음 중 고품질데이터의 특성이 아닌 것은?
① 정확성(Accuracy)
② 적시성(Timeliness)
③ 불편의성(Uncompleteness)
④ 일관성(Consistency)
③ 불편의성(Uncompleteness)
15. 다음 중 시스템의전방에 위치하여 클라이언트로부터 다양한 서비스를 처리하고, 내부 시스템으로 전달하는 미들웨어는?
① API 게이트웨이
② 데이터베이스
③ Paas
④ ESB(Enterprise Service Bus)
① API 게이트웨이
16. 데이터 3법에 포함되는 것이 아닌 것은?
① 개인정보보호법
② 정보통신산업 진흥법
③ 정보통신망 이용촉진 및 정보보호 등에 관한 법률
④ 신용정보의 이용 및 보호에 관한 법률
② 정보통신산업 진흥법
17. 공공데이터에서 제공하는 파일의 형식이 아닌 것은?
① xml
② Sql
③ Json
④ Csv
② Sql
18. 데이터 저장소가 아닌 것은?
① 데이터 웨어하우스
② 데이터 레이크
③ 데이터 마이닝
④ 데이터 댐
③ 데이터 마이닝
19. 데이터에 노이즈를 추가해 개인정보와 데이터분석을 모두 진행할 수 있는 방법은?
① K익명성
② 가명화
③ 개인정보차등보호
④ L다양성
③ 개인정보차등보호
20. 빅데이터 저장기술 중 옳은 것은?
① 맵리듀스
② 직렬화
③ 가시화
④ Nosql
④ Nosql
[2과목 빅데이터 탐색]
21. 다음 중 대표값관련 설명으로 옳지 않은 것은
① 평균은 중앙값보다 이상값에 영향을 더 적게 받는다.
② Q3-Q1같은 사분위수 범위를 의미한다.
③ 변동률 등은 기하 평균으로 구한다.
④ 변동계수는 분산과 관련이 있다.
① 평균은 중앙값보다 이상값에 영향을 더 적게 받는다.
22. 다음 표를 참고하여 귀무 가설 검정으로 옳은 것은?
사람의 평균수명을 알아보기 위해 사망자 100명을 표본으로 추출하여 조사하였더니 평균 72.4년으로 나타났다. 모표준편차를 12년으로 가정할 때, 현재의 평균수명은 70년보다 길다고 할 수 있는가를 검정하라(유의수준 a=0.05)
Z왼쪽 열은 2.5-3.0 까지 있었고 내부 데이터는 모두 0.99이상 값이었음.
① 표준정규확률변수 z=2, 귀무가설 채택
② 표준정규확률변수 z=2, 귀무가설 기각
③ 표준정규확률변수 z=3, 귀무가설 채택
④ 표준정규확률변수 z=3, 귀무가설 기각
② 표준정규확률변수 z=2, 귀무가설 기각
23. 다음 중 시공간데이터가 아닌 것은?
① 지도 데이터
② 패턴 데이터
③ 패널 데이터
④ 격자 데이터
② 패턴 데이터
24. 다음 중 이상값을 찾는 방법에 대한 설명이 아닌 것은?
① 박스플롯과 스캐터 플롯 등에서 멀리 떨어진 값
② 정규분포에서 표준편차가 3이상인 값
③ 도메인 지식에서 이론적이나 물리적으로 맞지 않는 값
④ 가설 검정의 노이즈 값
④ 가설 검정의 노이즈 값
25. 다음 중 주성분분석에 대한 설명으로 틀린 것은?
① 선형 결합하여 새로운 변수를 만든다.
② 분산이 커지도록 한다.
③ 데이터가 이산적인 경우에 사용한다.
④ 직관적으로 이해할 수 있다.
④ 직관적으로 이해할 수 있다.
26. 상관관계에 대한 설명 중 틀린 것은?
① 상관계수는 결정계수의 제곱이다.
② 범위는 -1에서 1사이 이다.
③ 0에 가까우면 상관성이 낮다.
④ 관계를 산점도로 알 수 있다.
① 상관계수는 결정계수의 제곱이다.
27. 정규 모집단 N(50,2²)에서 크기 n=16의 표본을 무작위 추출할때 표본평균 분포의 표준편차 또한 표본평균이 l=51이상일떄의 표준화 점수, 이에 대한 분포는?
① σₓ = 1/2, z=2, N(0,1)
② σₓ = 1, z=2, N(50,2²)
③ σₓ = 1/2, z=2, N(50,2²)
④ σₓ = 1, z=2, N(0,1)
① σₓ = 1/2, z=2, N(0,1)
28. 박스 플롯에서 3Q보다작은건?
① 중앙값
② 평균
③ 80퍼센트
④ Max값
① 중앙값
29. 자료의 분포가 오른쪽으로 긴꼬리일 경우에 대한 설명으로 맞는 것은?
① 왜도 > 0, 빈도수 < 중위수 < 평균
② 왜도 > 0, 평균 < 중앙값 < 최빈값
③ 왜도 < 0, 중앙값 < 최빈값 < 평균
④ 왜도 < 0, 최빈값 < 중앙값 < 평균
① 왜도 > 0, 빈도수 < 중위수 < 평균
30. 이산 확률 변수 X에 대해 E(X) = 4, E(X^2) = 25일 때, 확률 변수 Y = 3X - 4의 평균과 분산으로 옳은 것은?
① E(Y) = 8, V(Y) = 81
② E(Y) = 16, V(Y) = 9
③ E(Y) = 8, V(Y) = 25
④ E(Y) = 16, V(Y) = 81
① E(Y) = 8, V(Y) = 81
31. 정규화에 대한 설명으로 옳은 것은?
① Min-max 정규화 범위는 0과 1 사이 이다.
② 평균은 0, 표준편차는 1로 변환 하는 방법 이다.
③ 정규화를 표준화하면 표준정규분포다
④ Minmax 정규화보다 z값이 이상치에 영양을 덜 받는다.
① Min-max 정규화 범위는 0과 1 사이 이다.
32. 정규 분포의 설명이 아닌 것은?
① 왜도가 3, 첨도가 0이다.
② 직선 x=u(평균)에 대해여대칭인 종 모양의 곡선이다.
③ 곡선과 x축으로 둘러싸인 영역의 넓이는 1이다. (확률의 총합은 100%이다)
④ 곡선의 모양은 표준편차가 일정할 때, 평균이 변하면 대칭축의 위치와 곡선의 모양이 바뀐다.
① 왜도가 3, 첨도가 0이다.
33. 포아송 분포가 맞는지 적합도 검정을 한다.
| ㄱ. 하루에 몇회인지 평균을 구해야한다. ㄴ. 카이제곱 값이 클수록 귀무가설 기각 ㄷ. 자유도 4 |
① ㄱ,ㄴ
② ㄱ,ㄷ
③ ㄴ,ㄷ
④ ㄱ,ㄴ,ㄷ
① ㄱ,ㄴ
34. 각각의 사례에 알맞은 분석 방법으로 옳은 것은?
① 어떤 규칙이나 방법을 찾는데 회귀분석이나 군집분석을 사용 한다.
② 수요예측은 회귀분석 등 연속형 모델 등을 이용하여 분석 할 수 있고 인공신경망을 사용할 수도 있다.
③ 일정한 단위 시간의 변화에 따른 개개의 상품이나상품의 집합체에 관한 경제변량의 기본적인 관계를 나타내는 계수를 추정 및 분석하는 방법은 차원축소 분석을 사용한다.
④ 동일한 공간상에 비교한 상표들의 상대적 위치를 나타내는 분석방법은 요인분석이다.
② 수요예측은 회귀분석 등 연속형 모델 등을 이용하여 분석 할 수 있고 인공신경망을 사용할 수도 있다.
35. 비정형 텍스트 데이터 전처리 기법이 아닌 것은?
① Tokenizing
② API 이용
③ POS tagging
④ Stemming
② API 이용
36. 빅데이터 탐색에 대한 설명으로 적절하지 않은 것은?
① 빅데이터의 전체 분포를 검토하는 과정이다.
② 데이터 분석과정에서 결과를 도출한다.
③ 데이터 탐색 시 잠재적 문제를 발견하는 과정이다.
④ 데이터 탐색 시 패턴을 찾는 과정이다.
② 데이터 분석과정에서 결과를 도출한다.
37. 표준화와 점수분포에 관한 설명으로 적절한 것은?
① 표준화는 각 요소에서 평균을 뺀 값을 분산으로 나눈다.
② 표준화의 최대값은 1이다.
③ 표준화의 표준편차는 0이다.
④ 정규분포를 표준화하면 표준정규분포가 된다.
④ 정규분포를 표준화하면 표준정규분포가 된다.
38. 소수의 극단값의 영향을 받지 않으므로 변동성 척도로서 적절한 것은?
① 범위
② 변동계수
③ 사분위범위
④ 표준편차
③ 사분위범위
39. 초기하 분포의 설명으로 적절하지 않은 것은?
① 확률변수 값으로서 일정횟수의 베르누이 시행에서 성공횟수를 가진다.
② 성공확률은 일정하지 않다.
③ 각 시행은 독립적이다.
④ 이상형 확률분포를 따른다.
③ 각 시행은 독립적이다.
40. 다음과 같은 열이 4개인 박스플롯에 대한 설명으로 적절하지 않은 것은?
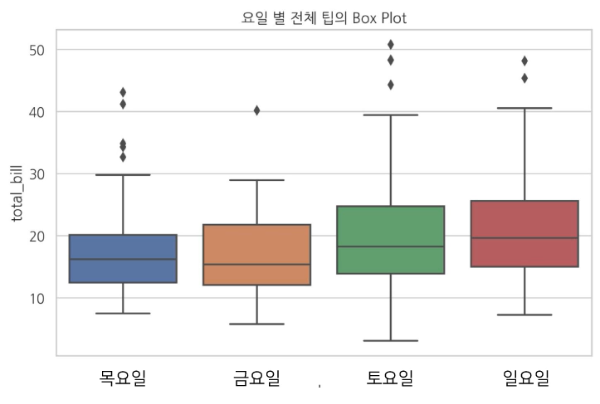
① 토요일의 분산은 금요일보다 크다.
② 금요일의 평균은 10에 가깝다.
③ 목요일의 1사분위수는 12에 가깝다.
④ 금요일에 이상값이 존재한다.
② 금요일의 평균은 10에 가깝다.
[3과목 빅데이터 모델링]
41. 텍스트 문맥 파악을 위해서 단어 단위로 끊어서 판별하는 기법은?
① 토픽 모델링
② 워드 클라우드
③ N-Gram
④ TFIDF
③ N-Gram
42. 선형회귀분석 오차항의 특성이 아닌 것은?
① 선형성
② 독립성
③ 정규성
④ 등분산성
① 선형성
43. 비지도학습에 대한 설명으로 다음 빈칸에 들어갈 말로 알맞은 것은?
정답을( ), ( )이 이에 속한다.
① 가르쳐주지 않고, 회귀분석
② 가르쳐주고, 회귀분석
③ 가르쳐주지 않고, 군집분석
④ 가르쳐주고, 군집분석
③ 가르쳐주지 않고, 군집분석
44. 인공지능에 대한 설명으로 가장 거리가 먼 것은?
① 모델 예측값과 실제값의 오차인 비용함수(Cost Function)는 인공지능 학습에서 최적화된 비용에 관련된 모든 변량에 대하여 어떤 관계를 나타내는 함수이다.
② 일반적으로 여러개의 은닉총을 가진 신경망을 통해 데이터를 학습 하는 것을 딥러닝이라 한다.
③ 딥러닝은 인공신경망으로 발전했다.
④ 인공지능이 기울기 소실 문제로 인해 암흑기가 발생한 적이 있다.
③ 딥러닝은 인공신경망으로 발전했다.
45. 인공신경망의 단층퍼셉트론 문제로 표현이 불가능한 논리회로는?
① AND
② OR
③ NOR
④ XOR
④ XOR
46. 오토인코더에 대한 설명으로 가장 잘못된 것은?
① 비지도 학습이다.
② 사전학습으로 사용된다.
③ 입력수는 은닉총 수보다 항상 작다.
④ 인코드 입력수와 디코드 출력수는 동일하다.
③ 입력수는 은닉총 수보다 항상 작다.
47. Boolean Function 나이브 베이지만 함수로 잘못된 것은?
① P(A,B|C) = P(A) X P(B|C)
② P(A,B,C|E) = P(A|C) X P(B|C) X P(C|C)
③ P(A,B|C) = P(A|C) X P(B|C)
④ P(A,E|C) = P(A|C) X P(E|C)
48. 의사결정나무에 대한 설명 중 틀린 것은?
① 가지에 하나가 남는 끝까지 진행한다.
② 변수를 하나 골라서 한계치 설정한다.
③ 나무구조에 의해 모델이 표현되기 때문에 해석이 용이한 편이다.
④ 분류 및 예측 목적으로 사용할 수 있다.
① 가지에 하나가 남는 끝까지 진행한다.
49. 범주형에 대한 분류방법이 아닌 것은?
① 인공신경망
② 선형회귀분석
③ 서포트 벡터머신
④ 의사결정나무
② 선형회귀분석
50. 다음이 설명하는 시계열의 특성은 무엇인가? (중장기적, 빈번한 발생 빈도가 없는 패턴)
① 추세
② 주기
③ 계절
④ 불규칙
② 주기
51. 연관분석기법으로 알맞은 것은?
① 회귀분석
② Apriori
③ 군집분석
④ 월콕슨순위합
② Apriori
52. 로지스틱 회귀분석에 대한 설명으로 잘못된 것은?
① 분류에 주로 사용한다.
② 자료형이 범주형을 갖는 경우 사용하는 분석기법이다.
③ Y값은 0과 1사이이다.
④ 대표적인 비지도 학습 알고리즘이다.
④ 대표적인 비지도 학습 알고리즘이다.
53. 비지도 학습 알고리즘 유형으로 알맞은 것은?
① 회귀분석
② 로지스틱 회귀분석
③ 서포트 벡터
④ 군집분석
④ 군집분석
54. 정준연결(Canonical link)의 로그함수로 알맞은 것은?
① 정규분포
② 베르누이
③ 포아송
④ 감마
③ 포아송
55. 통계에서 평균에 대한 차이검정으로 모집단 3개 이상 사용하는 분석방법으로 가장 알맞은 것은?
① t검정
② z검정
③ 분산분석
④ 상관분석
③ 분산분석
56. 비모수 통계 분석기법인 Willcoxon Signed rank와 Willcoxon rank sum 설명 중 가장 옳지 않은 것은?
① 윌콕슨 부호순위는 일변량 검정이다.
② 윌콕슨 순위합은 이변량 검정이다.
③ 주로 30개 이하의 작은 샘플일때 사용한다.
④ 윌콕슨 부호 순위 검정은 검정 결과가 대칭되어야 검정 가능하다.
④ 윌콕슨 부호 순위 검정은 검정 결과가 대칭되어야 검정 가능하다.
57. 아래의 수식이 나타내는 회귀는?
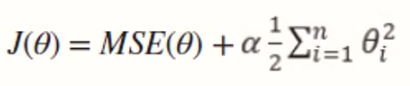
① 라쏘
② 릿지
③ 엘라스틱넷 회귀
④ 단순 회귀
② 릿지
58. 다음 설명 중 배깅에 대한 내용으로 가장 옳은 것은?
① 편향이 낮은 과소적합 모델을 사용한다.
② 편향이 높은 과대적합 모델을 사용한다.
③ 부트스트랩 자료를 생성하고 각 부트스트랩 자료를 결합하여 최종 예측모형 산출
④ 가중치를 활용하여 약 분류기를 강 분류기로 만드는방법
③ 부트스트랩 자료를 생성하고 각 부트스트랩 자료를 결합하여 최종 예측모형 산출
59. 초매개변수의 최적화로 옳지 않은 것은?
① 랜덤 서치
② 그리드 서치
③ 베이지안 최적화
④ 경사하강법
④ 경사하강법
60. 맨해튼 거리를 계산하시오 점A에서 2번째로 가까운 점의 거리는?
- 4개의 보기 A(1,1), B(1,2) C(2,2), D(4,1)
① 1
② 2
③ 3
④ 4
② 2
[4과목 빅데이터 결과 해석]
61. 시공간 시각화 기법 중 옳은 것은?
① 히스토그램
② 체르노프 페이스
③ 지도맵핑
④ 평행 좌표계
③ 지도맵핑
62. 실루엣 계수를 이용한 최적의 군집분석 갯수는?
① 2
② 3
③ 4
④ 5
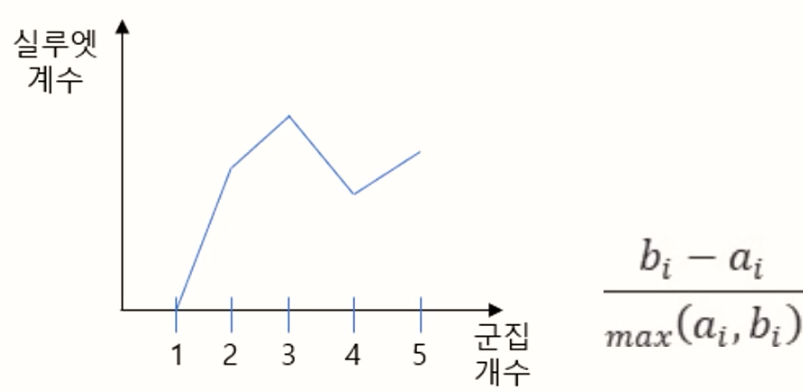
② 3
63. 다음 그래프의 이름으로 적절한 것은?
① 히트맵
② 트리맵
③ 영역차트
④ 누적영역차트
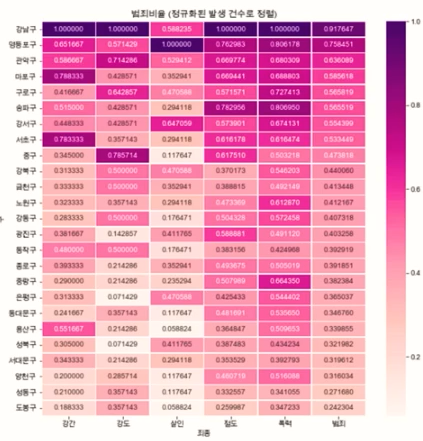
① 히트맵
64. 효과적인 인포그래픽의 조건 중 가장 적절하지 않은 것은?
① 인포메이션(Information과 시각적 그래프의 합성어이다.
② 최대한 많은 정보를 담는다.
③ 쉽게 이해할 수 있도록 그래픽과 텍스트를 조합해 사용한다.
④ 누적영역차트
② 최대한 많은 정보를 담는다.
65. y=0 혹은 y=1 값을 가지는 이진 분류 분석에서 y=1의 값이 y=0 값의 2배일 때, 민감도, 특이도, 정확도에 대한 설명으로 적절한 것은?
① 민감도와 특이도 둘다 1일때 정확도는 1이다.
② 특이도가 1일 때 정확도는 1/2이다.
③ 민감도가 1/2일 때 정확도는 1/2이다.
④ 민감도와 특이도가 같을 때 정확도도 특이도와 같다.
① 민감도와 특이도 둘다 1일때 정확도는 1이다.
66. 홀드아웃 관련 데이터가 아닌 것은?
① 검증데이터
② 학습데이터
③ 평가데이터
④ 증강데이터
④ 증강데이터
67. ROC 그래프의 설명으로 적절하지 않은 것은?
① 민감도가 1, 특이도가 0인 점을 지난다.
② 민감도가 0, 특이도가 1인점을 지난다.
③ 가장 이상적인 그래프는 민감도가 1, 특이도가 1인 점을 지난다.
④ 특이도가 증가하는 그래프이다.
④ 특이도가 증가하는 그래프이다.
68. A상품에 대한 인지도 조사결과가 아래와 같을 때, 이에 대한 설명으로 옳은 것은?
| 알고있음 | 모름 | 합계 | |
| 아이가 있는 남자(명) | 460 | 40 | 500 |
| 아이가 없는 남자(명) | 440 | 60 | 500 |
| 합계 | 900 | 100 | 1000 |
① A제품을 알고있을 확률은 0.90이다.
②아이가 있는 남자이면서 A제품을 모르고 있을 확률은 0.04이다.
③ 아이가 없는 남자이면서 A제품을 모르고 있을 확률은 0.06이다.
④ 아이가 있는 남자 중에서 A제품을 알고 있을 확률은 약 0.92이다.
※중복 정답
① A제품을 알고있을 확률은 0.90이다.
④ 아이가 있는 남자 중에서 A제품을 알고 있을 확률은 약 0.92이다.
69. 다음 관측값에 대한 설명으로 옳지 않은 것은?
| 54, 46, 60, 40 |
① 기대빈도 50
②비율이 p1 = p2 = p3 = p4 = 1/4
③ 카이제곱 값이 4.64
④ 카이제곱(3) = 7.8이라면, 귀무가설을 기각한다.
④ 카이제곱(3) = 7.8이라면, 귀무가설을 기각한다.
70. 포아송 분포가 맞는지 적합도 검정을 한다면 보기중 가장 알맞는 것은?
① 연속형 확률 분포에서 주로 사용한다.
② 유의 수준은 사용하지 않는다.
③ P-value가 유의수준보다 작으면 귀무가설을 기각한다.
④ 람다는 어떤 일정 시간과 공간의 구간 안에서 발생한 평균 사건 수를 의미하지 않는다.
71. 비교 그래프가 아닌것은?
① 막대그래프
② 레이더차트
③ 히트맵
④ 산점도
④ 산점도
72. K-fold CV에 대한 설명 중 옳지 않은 것은?
① 검증, 훈련, 테스트 데이터로 이루어져 있다.
② k=3 이상만 가능
③ k개의 균인한 서브셋
④ k-1개의 부분집합을 학습데이터로 사용
② k=3 이상만 가능
73. 누적 히스토그램에 대한 설명으로 가장 알맞은 것은?
① 범주형과 수치형 모두의 분포를 알 수 있다.
② 히스토그램의 y축을 평균으로도 나타낼 수 있다.
③ 계급수를 잘 정해야 정확한 분포 파악이 가능하다.
④ 누적확률분포표는 누적확률밀도함수와 비슷한 형태를 보인다.
③ 계급수를 잘 정해야 정확한 분포 파악이 가능하다.
74. 과대적합일 때 대응방법이 아닌 것은?
① Regularization
② Batch Nomalization
③ Drop-out
④ Max Pooling
④ Max Pooling
75. 회귀분석 log(odds) = a + bx 설명으로 가장 거리가 먼것은?
① a,b 둘다 0이면 y확률 0이다.
② Log 연산을 통해 0에서 1사이의 Logit을 획득한다.
③ 오즈(Odds)는 클래스 0에 속하는 확률에 대한 클래스 1에 속하는 확률의 비이다.
④ 승산비(Odd Ratio)사건이 발생한 확률과 발생하지 않을 확률 간의 비율이다.
① a,b 둘다 0이면 y확률 0이다.
76. 혼돈행렬에서의 FN 해석에 대한 것으로 알맞은 것은?
① 예측값 False 실제값 False
② 예측값 False 실제값 True
③ 예측값 True 실제값 False
④ 예측값 True 실제값 True
② 예측값 False 실제값 True
77. 데이터 불균형이 있을 경우 사용하는 평가지표로 옳지 않은 것은?
① 민감도
② 정확도
③ 오분류율
④ ROC곡선
② 정확도
78. 보고서 작성시 방법으로 가장 거리가 먼 것은?
① 전문용어를 많이 사용한다.
② 쉽게 이해할 수 있도록 작성한다.
③ 비즈니스에 사용할 수 있도록 한다.
④ 보고서를 통해 성과 기준과 기여도를 표현할 수 있도록 한다.
① 전문용어를 많이 사용한다.
79. 회귀계수의 유의성 검정? (유사한 유형)
어느 중학교에서 1학년 학생들의 키의 차이가 2학년이 되면 더 커질 것이라고 예상된다. 1학년에서 6명을 뽑고, 2학년에서 8명을 뽑아서 각각의 성적의 분산을 조사해 봤더니, 1학년의 분산은 10.0이었고 2학년의 분산은 50.0이었다. 두 모집단의 분산은 같다고 볼 수 있을까?
a=0.05에서 검정해보자.
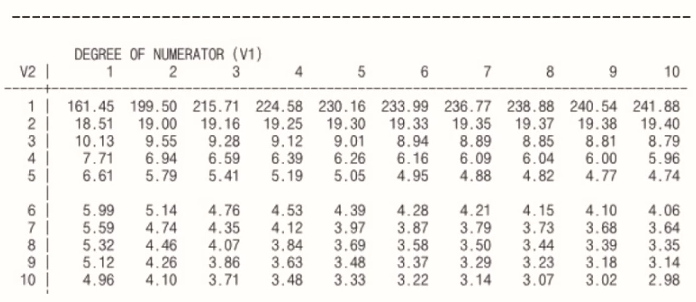
① F통계량, p-value < 유의수준, 귀무가설 채택
② F통계량, p-value < 유의수준, 귀무가설 기각
③ 카이제곱, p-value < 유의수준, 귀무가설 채택
④ 카이제곱, p-value < 유의수준, 귀무가설 기각
② F통계량, p-value < 유의수준, 귀무가설 기각
80. 분석모형 리모델링 및 활용 과정별 명칭과 그 내용에 대하여 잘못짝지어진 것은?
정의 → 표준화 → ( ) → 일반화
① 정규화
② 최적화
③ 합리화
④ 중복제거
② 최적화
'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| 빅데이터분석기사 필기 - 분류 모형의 평가지표(혼동 행렬, ROC 곡선, 이익 도표) 개념과 기출문제 (0) | 2022.10.01 |
|---|---|
| 빅데이터분석기사 필기 - 불균형 데이터 처리 방법과 기출문제 (0) | 2022.10.01 |
| [빅데이터분석기사 필기] 변수 변환 방법과 기출문제 (0) | 2022.10.01 |
| [빅데이터분석기사 필기] 서포트 벡터 머신(SVM)의 개념과 기출문제 (0) | 2022.10.01 |
| [빅데이터분석기사 필기] 2021년 2회차 기출문제 (2) | 2022.09.30 |