빅데이터분석기사 필기 4과목에서 가장 많이 나오는 유형이므로 모든 내용을 이해 후 암기하셔야 합니다. 특히 혼동 행렬은 시험당 3~4문제가 출제됩니다. 평가지표와 공식은 모두 암기해주세요. 또한 ROC 곡선문제도 1~2문제 출제되며 F1 Score와 카파통계량 중 한문제가 출제됩니다.
분류 모형의 평가지표
- 분류 모형의 결과를 평가하기 위해서 혼동 행렬을 이용한 평가지표와 ROC곡선의 AUC를 많이 사용한다.
- 모형의 평가지표가 우연히 나온 결과가 아니라는 것을 카파통계량을 통하여 설명할 수 있다.
① 혼동 행렬
- 혼동 행렬은 분석 모델에서 구한 분류의 예측 범주와 데이터의 실제 분류 범주를 교차 표 형태로 정리한 행렬이다.
- 혼동 행렬을 작성함에 따라 모델의 성능을 평가할 수 있는 평가지표가 도출된다.
- 모델의 정확도를 예측값과 실제값의 일치 빈도를 통해 평가할 수 있다.
- TP : 실제값이 Positive이고 예측값도 Positive인 경우
- TN : 실제값이 Negative이고 예측값도 Negative인 경우
- FP : 실제값이 Negative이었으나 예측값은 Positive인 경우
- FN : 실제값이 Positive이었으나 예측값은 Negative인 경우
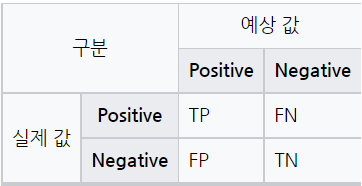
⭐ 혼동 행렬을 통한 분류 모형의 평가지표
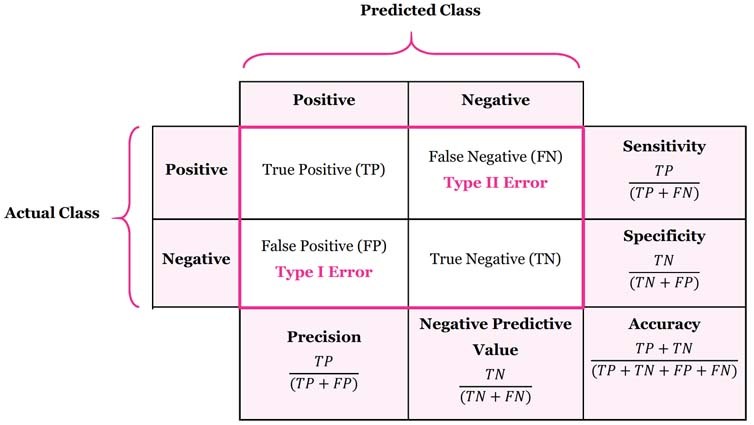
- 정확도(Accuray) = 정분류율 : 실제 분류 범주를 정확하게 예측한 비율
- 오차 비율(Error Rate) : 실제분류 범주를 잘못 분류한 비율
- 참 긍정률(TP Rate) = 재현율(Recall) = 민감도(Sensitivity) : 실제로 '긍정'인 범주 중에서 '긍정'으로 올바르게 예측한 비율
- 특이도(Specificity) : 실제로 '부정'인 범주 중에서 '부정'으로 올바르게 예측한 비율
- 거짓 긍정률(FP Rate) : 실제로 '부정'인 범주 중에서 '긍정'으로 잘못 예측한 비율
- 정밀도(Precision) : 긍정으로 예측한 비율 중에서 실제로 '긍정'인 비율
- F-Measure(F1-Score)
- 정밀도(Precision)와 민감도(Sensitivity)를 하나로 합한 성능평가 지표
- 0 ~ 1 사이의 범위를 가짐
- 정밀도와 민감도 양쪽이 모두 끌 때 F-Measure도 큰 값을 가짐
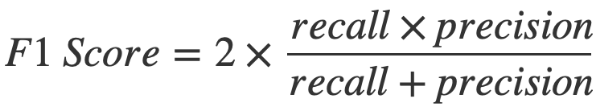
- 카파 통계량
- 두 관찰자가 측정한 범주 값에 대한 일치도를 측정하는 방법
- 0~1의 값을 가지며 1에 가까울수록 모델의 예측값과 실젯값이 정확히 일치하며, 0에 가까울수록 모델의 예측값과 실젯값이 불일치
- 정확도 외에 카파 통계량을 통해 모형의 평가 결과가 우연히 나온 결과가 아니라는 것을 설명
② ROC 곡선
- ROC곡선은 가로축을 혼동 행렬의 거짓 긍정률(FP Rate)로 두고 세로축을 참 긍정률(TP Rate)로 두어 시각화한 그래프이다.
- ROC 곡선은 그래프가 왼쪽 꼭대기에 가깝게 그려질수록 분류 성능이 우수하다.
- FP Rate와 TP Rate는 어느 정도 비례 관계에 있다.
- AUC는 진단의 정확도를 측정할 때 사용하는 것으로 ROC 곡선 아래의 면적을 모형의 평가지표로 삼는다.
- AUC의 값은 항상 0.5 ~ 1의 값을 가지며 1에 가까울수록 좋은 모형이다.
- AUC(Area Under ROC) 0.5일 경우, 랜덤 선택에 가까운 성능을 보인다.

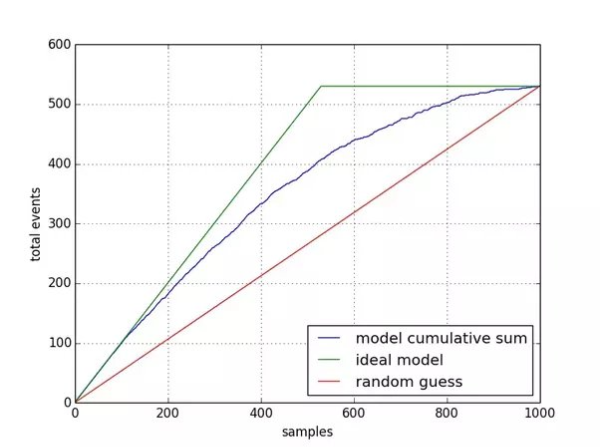
③ 이익도표
- 분류 모형의 성능을 평가하기 위해서 사용되는 그래프 분석 방법이다.
- 이익은 목표 범주에 속하는 개체들의 임의로 나눈 등급별로 얼마나 분포하고 있는지를 나타내는 값이다.
- 이익 도표는 이익 곡선, 리프트 곡선이라고도 부른다.
분석 모형의 평가지표 기출문제
Q. 다음 중 분석 모형의 평가방법에 대한 설명으로 틀린 것은? [2회차]
① 종속변수의 유형에 따라 선택하는 평가방법이 다르다.
② 종속변수의 유형이 범주형일 때는 혼동 행렬을 사용할 수 있다.
③ 종속변수의 유형이 연속형일 때는 RMSE를 사용할 수 있다.
④ 종속변수가 범주형일 때 임곗값이 바뀌면 정분류율은 변하지 않는다.
④ 종속변수가 범주형일 때 임곗값이 바뀌면 정분류율은 변하지 않는다.
Q. 다음은 암 진단을 예측한 것과 실제 암 진단 결과를 혼동행렬로 나타낸 것이다. 아래 표를 보고 TPR, FPR의 확률을 구계산하시오. ( 단, 결과가 음성이라는 뜻인 0을 Positive로한다.)

① TPR : 9/10, FPR : 1/4
② TPR : 9/10, FPR : 1/48
③ TPR : 3/4, FPR : 1/48
④ TPR : 3/4, FPR : 1/4
③ TPR : 3/4, FPR : 1/48
Q. 다음은 혼동 행렬(Confusion Matrix)에서 참이 0이고 거짓이 1일 때, Specificity와 Precision은 무엇인가? [2회차]
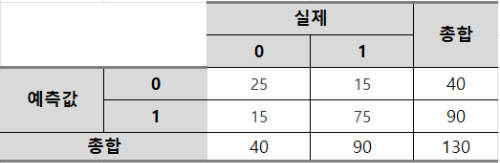
① Specificity : 5/8, Precision : 5/8
② Specificity : 5/8, Precision : 5/6
③ Specificity : 5/6, Precision : 5/6
④ Specificity : 5/6, Precision : 5/8
④ Specificity : 5/6, Precision : 5/8
Q. 다음 중 혼동 행렬에 대한 설명으로 적절하지 않은 것은? [2회차]
① 카파 값(Kappa Value)은 0~1 사이의 값을 가지며, 1에 가까울수록 예측값과 실젯값이 일치함을 알 수 있다.
② 부정인 범주 중 부정으로 올바르게 예측한 비율은 민감도(Sensitivity)지표를 사용한다.
③ 부정인 범주 중 긍정으로 잘못 예측(False Positive)한 비율을 정밀도 라고 하며 TP/(TP+FP)라고 표기한다.
④ 머신러닝 성능 평가지표 중 정확도를 표기하는 식은 (TP+TN)/(TP+FP+FN+TN)이다.
② 부정인 범주 중 부정으로 올바르게 예측한 비율은 민감도(Sensitivity)지표를 사용한다.
③ 부정인 범주 중 긍정으로 잘못 예측(False Positive)한 비율을 정밀도 라고 하며 TP/(TP+FP)라고 표기한다.
오류문제 정답두개
Q. 다음 중 F1-Score에 들어가는 지표는? [2회차]
① TP Rate, FP Rate
② Accuracy, Sensitivity
③ Specificity, Error Rate
④ Precision, Recall
④ Precision, Recall
Q. 다음 중 ROC 커브에 대한 설명으로 적합하지 않은 것은? [2회차]
① x축은 특이도를 의미한다.
② y축은 민감도를 의미한다.
③ AUC(Area Under ROC) 1.0에 가까울수록 분석 모형성능이 우수하다.
④ AUC(Area Under ROC) 0.5일 경우, 랜덤 선택에 가까운 성능을 보인다.
① x축은 특이도를 의미한다.
Q. ROC 곡선에 대한 설명으로 적절하지 않은 것은? [4회차]
① 민감도가 1, 특이도가 0인 점을 지난다.
② 민감도가 0, 특이도가 1인점을 지난다.
③ 가장 이상적인 그래프는 민감도가 1, 특이도가 1인 점을 지난다.
④ 특이도가 증가하는 그래프이다.
④ 특이도가 증가하는 그래프이다.
Q. 혼돈행렬에서의 FN 해석에 대한 것으로 알맞은 것은? [4회차]
① 예측값 False 실제값 False
② 예측값 False 실제값 True
③ 예측값 True 실제값 False
④ 예측값 True 실제값 True
② 예측값 False 실제값 True
Q. 데이터 불균형이 있을 경우 사용하는 평가지표로 옳지 않은 것은? [4회차]
① 민감도
② 정확도
③ 오분류율
④ ROC곡선
② 정확도
불균형 데이터인 경우에는 정확도를 사용하면 안된다. 만약 데이터의 균형이 9:1일 때, 머신러닝의 정확도는 90%가 되기 때문이다.
'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사 필기] 2022년 제4회 기출문제 (13) | 2024.11.27 |
|---|---|
| 빅데이터분석기사 필기 - 불균형 데이터 처리 방법과 기출문제 (0) | 2022.10.01 |
| [빅데이터분석기사 필기] 변수 변환 방법과 기출문제 (0) | 2022.10.01 |
| [빅데이터분석기사 필기] 서포트 벡터 머신(SVM)의 개념과 기출문제 (0) | 2022.10.01 |
| [빅데이터분석기사 필기] 2021년 2회차 기출문제 (2) | 2022.09.30 |