2021년 제2회 기출문제
2021년 4월 17일에 시행된 빅데이터 분석기사 필기 4회 기출문제입니다. 총 80문항이며 100점을 만점으로 하여 과목당 40점 이상, 전 과목 평균 60점 이상이면 합격입니다. 실제 시험과 100% 일치하지는 않습니다. 정답 버튼을 클릭하시면 정답을 보실 수 있고 에러 사항이 있으면 댓글을 달아 주시면 바로 수정하겠습니다.
[1과목 빅데이터 분석 기획]
1. 다음 중 수집 대상 데이터를 추출, 가공하여 데이터 웨어하우스 및 데이터 마트에 저장하는 기술은 무엇인가?
① ETL
② CEP
③ EAI
④ ODS
① ETL
2. 딥러닝에 대한 설명으로 옳은 것은?
① 오차 역전파를 사용한다.
② ReLU보다 Sigmoid를 사용한다..
③ 딥러닝은 각 은닉층의 가중치를 통해 모형의 결과를 해석하기 용이하다.
④ Dropout은 일정한 비율로 신경망을 제거한다..
① 오차 역전파를 사용한다.
3. 다음 중 빅데이터 분석 방법론 절차로 옳은 것은 무엇인가?
① 분석 기획 → 데이터 준비 → 데이터 분석 → 평가 및 전개 → 시스템 구현
② 분석 기획 → 데이터 준비 → 데이터 분석 → 시스템 구현 → 평가 및 전개
③ 데이터 준비 → 분석 기획 → 데이터 분석 → 시스템 구현 → 평가 및 전개
④ 데이터 준비 → 분석 기획 → 데이터 분석 → 평가 및 전개 → 시스템 구현
② 분석 기획 → 데이터 준비 → 데이터 분석 → 시스템 구현 → 평가 및 전개
4. 다음 중 Label을 통해서만 학습하는 기법으로 옳은 것은??
① 지도 학습
② 비지도 학습
③ 강화 학습
④ 준지도 학습
① 지도 학습
5. 다음 중 비식별화 조치에 대한 설명으로 옳지 않은 것은?
① k-익명성은 주어진 데이터 집합에서 식별자 속성들이 동일한 레코드가 적어도 k개 이상 존재해야 한다.
② l-다양성은 l개의 서로 다른 민감정보를 가져야한다.
③ t-근접성은 특정 정보의 분포와 전체 데이터 집합에서 정보의 분포가 t 이상의 차이를 보이도록 해야 한다.
④ m-유일성은 원본 데이터와 동일한 속성 값의 조합이 비식별 결과 데이터에 최소 m개가 존재해야 한다.
③ t-근접성은 특정 정보의 분포와 전체 데이터 집합에서 정보의 분포가 t 이상의 차이를 보이도록 해야 한다.
6. 익명화 기법이 아닌 것은?
① 가명 처리
② 특이화
③ 치환
④ 섭동
② 특이화
7. 기술통계에 해당하지 않는 것은 무엇인가?
① 평균
② 분산
③ 가설검정
④ 시각화
③ 가설검정
8. 다음 중 분석의 대상이 무엇인지를 인지하고 있는 경우, 즉 해결해야 할 문제를 알고 있고 이미 분석의 방법도 알고 있는 경우 사용하는 분석 기획 유형은?
① 최적화(Otimization)
② 솔루션(Solution)
③ 통찰(Insight)
④ 발견(Discovery)
① 최적화(Otimization)
9. 개인정보 수집 시 동의를 얻지 않아도 되는 경우로 옳지 않은 것은?
① 사전 동의를 받을 수 없는 경우로서 명백히 정보 주체 또는 제3자의 급박한 생명, 신체, 재산의 이익을 위하여 필요하다고 인정되는 경우
② 입사 지원자에 대해 회사가 범죄경력을 조회하는 경우
③ 정보 주체와의 계약의 체결을 위하여 불가피하게 필요한 경우
④ 요금 부과를 위해 회사가 사용자의 정보를 조회하는 경우
② Volume
10. 수집된 정형 데이터 품질 보증을 위한 방법으로 적합하지 않은 것은?
① 데이터 프로파일링 - 정의된 표준 도메인에 맞는지 검증한다.
② 메타 데이터 분석 - 실제 운영 중인 데이터베이스의 테이블명·칼럼명·자료형·도메인·제약조건 등이며 데이터베이스 설계에는 반영되지 않은 한글 메타데이터·도메인 정보·엔티티 관계·코드 정의 등도 검증한다.
③ 데이터 표준-데이터 표준 준수 진단, 논리/물리 모델 표준에 맞는지 검증한다.
④ 비업무 규칙 적용 - 업무 규칙에 정의되어 있지 않는 값을 검증한다.
④ 비업무 규칙 적용 - 업무 규칙에 정의되어 있지 않는 값을 검증한다.
11. 데이터가 가지고 있는 특성을 파악하기 위해 해당 변수의 분포 등을 시각화하여 분석하는 분석방식은 무엇인가?
① 전처리 분석
② 탐색적 데이터 분석(EDA)
③ 공간 분석
④ 다변량 분석
② 탐색적 데이터 분석(EDA)
12. 빅데이터 분석 절차에서 문제의 단순화를 통해 변수 간의 관계로 정의하는 것을 무엇이라고 하는가?
① 연구 조사
② 탐색적 데이터 분석
③ 요인 분석
④ 모형화
③ 요인 분석
13. 다음 중 진단 분석(Diagnosis Analysis)에 대한 설명으로 가장 적합한 것은?
① 과거에 어떤 일이 일어났고 현재는 무슨 일이 일어나고 있는지?
② 데이터를 기반으로 왜 발생했는지?
③ 무슨 일이 일어날 것인지?
④ 어떤 대응을 해야 하는지?
② 데이터를 기반으로 왜 발생했는지?
14. 데이터 이상값 발생 원인으로 옳지 않은 것은?
① 측정 오류(Measurement Error)
② 보고 오류(Reporting Error)
③ 처리 오류(Processing Error)
④ 표본 오류(Sampling Error)
② 보고 오류(Reporting Error)
15. 다음 중 데이터 수집 방법으로 가장 적절하지 않은 것은?
① Open API로 센서 데이터를 수집한다.
② FTP를 통해 문서를 수집한다.
③ 동영상 데이터는 스트리밍(Streaming)을 통해 수집한다.
④ DBMS로부터 크롤링한다.
④ DBMS로부터 크롤링한다.
16. 조직을 평가하기 위한 성숙도 단계로 적절하지 않은 것은?
① 도입
② 최적화
③ 활용
④ 인프라
④ 인프라
17. 개인정보 주체자가 개인에게 알리지 않아도 되는 사실로 옳지 않은 것은?
① 동의를 거부할 수 있는 권리
② 개인정보의 수집 보유 및 이용기간
③ 개인정보 파기 사유
④ 개인정보 수집 항목
③ 개인정보 파기 사유
18. 프로세스 분석을 통한 분석 기회 발굴 절차로 올바른 것은 무엇인가?
① 프로세스 분류 → 프로세스 흐름 분석 → 분석 요건 식별 → 분석 요건 정의
② 프로세스 흐름 분석 → 프로세스 분류 → 분석 요건 식별 → 분석 요건 정의
③ 프로세스 흐름 분석 → 프로세스 분류 → 분석 요건 정의 → 분석 요건 식별
④ 프로세스 분류 → 프로세스 흐름 분석 → 분석 요건 정의 → 분석 요건 식별
① 프로세스 분류 → 프로세스 흐름 분석 → 분석 요건 식별 → 분석 요건 정의
19. 수집 데이터의 메타데이터 등 설명이 누락되거나 충분하지 않을 경우 자료 활용성에 있어 어떤 문제점 및 결함이 존재하는지 여부를 확인하는 품질 검증 기준은 무엇인가?
① 유용성
② 완전성
③ 일관성
④ 정확성
② 완전성
20. 다음이 설명하는 모델은 무엇인가?
기업에서 사용하는 데이터의 가용성, 유용성, 통합성, 보안성을 관리하기 위한 정책과 프로세스를 다루며 프라이버스, 보안성, 데이터 품질, 관리 규정 준수를 강조하는 모델
① K익명성
② 가명화
③ 개인정보 차등 보호
④ L다양성
③ 개인정보 차등 보호
[2과목 빅데이터 탐색]
21. 시각적 데이터 탐색에서 자주 사용되는 박스 플롯(Box-Plot)으로 알 수 없는 통계량은 무엇인가?
① 평균
② 분산
③ 이상값
④ 최댓값
① 평균
22. 모든 변수가 포함된 모형에서 시작하여 영향력이 가장 작은 변수를 하나씩 삭제하는 변수 선택 기법은 다움 중 무엇인가?
① 후진 소거법
② 전진 선택법
③ 단계적 방법
④ 필터 기법
① 후진 소거법
23. 다음 중 머신 러닝에서 훈련 데이터의 클래스가 불균형한 문제를 처리하는 방법에 대한 설명으로 가장 옳지 않은 것은 무엇인가?
① 과소 표집(Under-Sampling)은 많은 클래스의 데이터 일부만 선택하는 기법으로 정보가 유실되는 단점이 있다.
② 과대 표집(Over-Sampling)은 소수 데이터를 복제해서 많은 클래스의 양만큼 증가시키는 기법이다.
③ 불균형 문제를 처리하지 않으면 정확도(Accuracy)는 낮아지고 작은 클래스의 재현율(Recall)은 높아진다.
④ 클래스가 불균형한 훈련 데이터를 그대로 이용할 경우 과대 적합 문제가 발생할 수 있다.
③ 불균형 문제를 처리하지 않으면 정확도(Accuracy)는 낮아지고 작은 클래스의 재현율(Recall)은 높아진다.
24. 다음 중 파생변수 생성 방법으로 가장 올바르지 않은 것은?
① 주어진 변수의 단위 혹은 척도를 변환하여 새로운 단위로 표현
② 요약 통계량 등을 활용
③ 다양한 함수 등 수학적 결합을 통해 새로운 변수를 정의
④ 소수의 데이터를 복제하여 생성한다.
④ 소수의 데이터를 복제하여 생성한다.
25. 한 회사에서 A 공장은 부품을 50% 생산하고 불량률은 1%이다. B공장은 부품을 30% 생산하고 불량률은 2%이고, C공장은 부품을 20% 생산하고 불량률은 3%이다. 불량품이 발생하였을 때 C공장에서 생산한 부품일 확률은 얼마인가?
① 1/3
② 6/17
③ 1/2
④ 3/5
② 6/17
26. 모표준편차 σ = 8인 정규분포를 따르는 모집단에서 표본의 크기가 25인 표본을 추출하였을 때 표본평균은 90이다. 모평균 μ에 대한 90% 신뢰구간을 구하여라. (단, Z₀.₀₅ = 1.645, Z₀.₀₂₅ = 1.96이다.)
① 86.864 ≤ μ ≤ 93.136
② 87.368 ≤ μ ≤ 92.632
③ 87.368 ≤ μ ≤ 93.136
④ 86.864 ≤ μ ≤ 92.632
② 87.368 ≤ μ ≤ 92.632
27. 다음의 확률 밀도 함수로부터 표본 3,1,2,3,3이 추출되었다. 최대우도 추정법을 이용해 에 대한 최대우도 추정 값을 구하시오.
① 1/3
② 5/12
③ 1/2
④ 5/14
② 5/12
28. 산점도에 대한 설명으로 옳은 것을 모두 고른 것은?
가. 관계 시각화의 유형이다.
나. 직교 좌표계를 이용하여 좌표상의 점들을 표현하는 시각화 기법이다.
다. 두 변수 사이의 상관관계를 알 수 있다.
① 가
② 나
③ 다
④ 가, 나, 다
④ 가, 나, 다
29. 두 변수 간에 직선 관계가 있는지를 나타낼 때 가장 적절한 통계량은 다음 중 무엇인가?
① F-통계량
② t-통계량
③ p-값
④ 표본상관계수
④ 표본상관계수
30. 아래에서 설명하는 시각화 기법은 어떤 차트를 설명하고 있는가?
- 여러 축을 평행으로 배치하는 비교 시각화 기술이다.
- 수직선엔 변수를 배치한다.
- 측정 대상은 변숫값에 따라 위아래로 이어지는 연결선으로 표현한다.
① 산점도
② 박스 플롯
③ 스타 차트
④ 평행 좌표계
④ 평행 좌표계
31. A고등학교에서 남학생 25명을 대상으로 키를 측정하였더니 평균 170cm이고, 분산이 25이다. A고등학교 남학생의 평균 키에 대한 95% 신뢰구간은 얼마인가?

① 167.836 ≤ 키 ≤ 172.064
② 167.940 ≤ 키 ≤ 172.060
③ 168.289 ≤ 키 ≤ 171.711
④ 168.292 ≤ 키 ≤ 171.708
① 167.836 ≤ 키 ≤ 172.064
32. 다음 중 추론 통계에 대한 설명으로 가장 올바르지 않은 것은 무엇인가?
① 표본의 개수가 많을수록 표준 오차는 커진다.
② 신뢰구간은 신뢰 수준을 기준으로 추정된 통계적으로 유의미한 모수의 범위이다.
③ 점 추정은 모집단의 모수를 하나의 값으로 추정하는 것이다.
④ 신뢰 수준은 추정 값이 존재하는 구간에 모수가 포함될 확률을 말한다.
① 표본의 개수가 많을수록 표준 오차는 커진다.
33. 다음 중 빈칸에 알맞은 값은?
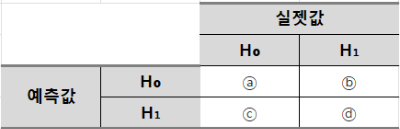
① ⓐ: 제1종 오류, ⓑ: 올바른 결정 ⓒ: 제2종 오류, ⓓ: 올바른 결정
② ⓐ: 제2종 오류, ⓑ: 올바른 결정 ⓒ: 제1종 오류, ⓓ: 올바른 결정
③ ⓐ: 올바른 결정, ⓑ: 제2종 오류 ⓒ: 제1종 오류, ⓓ: 올바른 결정
④ ⓐ: 올바른 결정, ⓑ: 제1종 오류 ⓒ: 올바른 결정, ⓓ: 제2종 오류
③ ⓐ: 올바른 결정, ⓑ: 제2종 오류 ⓒ: 제1종 오류, ⓓ: 올바른 결정
34. 다음 중에서 주성분 분석에 대한 설명으로 가장 적절하지 않은 것은?
① 여러 변수 간에 내재하는 상관관계, 연관성을 이용해 소수의 주성분으로 차원을 축소한다.
② 수요예측은 회귀분석 등 연속형 모델 등을 이용하여 분석할 수 있고 인공신경망을 사용할 수도 있다.
③ 데이터 간 높은 상관관계가 존재하는 상황에서 상관관계를 제거할 경우 분석이 어려워진다.
④ 스크리 산점도의 기울기가 완만해지기 직전까지 주성분의 수로 결정할 수 있다.
③ 데이터 간 높은 상관관계가 존재하는 상황에서 상관관계를 제거할 경우 분석이 어려워진다.
35. 다음 사례에서 설명하는 A 야구팀 연봉의 대푯값을 구하기 위한 가장 적절한 통계량은 무엇인가?
A 야구 구단의 상위 1~2명이 구단 전체 연봉의 50% 이상을 차지하며 나머지 선수들의 연봉은 일반적인 범주에 있다.
① 평균
② 최빈수
③ 중위수
④ 이상값
③ 중위수
36. 다음에서 설명하는 표본추출 방법은 무엇인가?
- 다수의 이질적인 원소들로 구성된 모집단에서 각 계층을 고루 대표할 수 있도록 표본을 추출하는 방법이다. 이질적인 모집단의 원소들로 서로 유사한 것끼리 몇 개의 층을 나눈 후, 각 계층에서 표본을 랜덤 하게 추출한다.
① 층화 추출법
② 계통추출법
③ 군집 추출법
④단순 무작위 추출법
① 층화 추출법
37. 각 클래스의 데이터에 불균형이 발생한 경우 학습 단계에서의 처리 방법으로 가장 옳지 않은 것은?
① 과소 표집(Under-Sampling)
② 과대 표집(Over-Sampling)
③ 임계값(Cut-off Value)
④ 가중치(Weight) 적용
③ 임계값(Cut-off Value)
38. 다음 중에서 분포의 성격이 다른 분포는 무엇인가?
① 정규분포
② 이항 분포
③ F-분포
④ 지수 분포
② 이항 분포
39. 다음 중에서 확률 분포에 대한 설명으로 가장 올바르지 않은 것은 무엇인가?
① 포아송 분포는 독립적인 두 카이제곱 분포가 있을 때, 두 확률 변수의 비이다.
② 카이제곱 분포는 서로 독립적인 표준 정규 확률 변수를 각각 제곱한 다음 합해서 얻어지는 분포이다.
③ T-분포는 모집단이 정규분포라는 정도만 알고 모 표준편차는 모를 때 모집단의 평균의 추정을 위하여 사용한다.
④ 베르누이 분포는 특정 실험의 결과가 성공 또는 실패로 두 가지의 결과 중 하나를 얻는 확률 분포이다.
① 포아송 분포는 독립적인 두 카이제곱 분포가 있을 때, 두 확률 변수의 비이다.
40. 다음 중 T-분포와 Z-분포에 대한 설명으로 가장 적절하지 않은 것은?
① 표본의 크기가 작은 소표분의 경우 T-분포를 사용한다..
② 표본의 크기가 큰 대표본의 경우에는 Z-분포를 사용한다.
③ Z-분포의 평균은 0이고 분산은 1이다.
④ 표본의 크기와 상관없이 T-분포는 정규분포를 따른다.
④ 표본의 크기와 상관없이 T-분포는 정규분포를 따른다.
[3과목 빅데이터 모델링]
41. 가장 적은 영향을 주는 변수부터 하나씩 제거하면서 더 이상 유의하지 않은 변수가 없을 때까지 설명변수들을 제거하고 이때의 모형을 선택하는 방법은 무엇인가?
① 중위 선택법
② 전진 선택법
③ 후진 소거법
④ 단계적 방법
③ 후진 소거법
42. 인공신경망은 어떤 값을 알아내는 게 목적인가?
① 커널값
② 뉴런
③ 가중치
④ 오차
③ 가중치
43. CNN에서 원본 이미지가 5*5에서 Stride가 1이고, 필터가 3*3일 때 Feature Map은 무엇인가?
① (1, 1)
② (2, 2)
③ (3, 3)
④ (4, 4)
③ (3, 3)
44. 선형 회귀 모형의 가정에서 잔차항과 관련 없는 것은?
① 선형성
② 독립성
③ 등분산성
④ 정상성
① 선형성
45. 서포트 벡터 머신에 대한 설명으로 옳지 않은 것은?
① 다른 모형에 비해 속도가 빠르다.
② 다른 모형보다 과대 적합에 강하다.
③ 비선형으로 분류되는 모형에도 사용할 수 있다.
④ 서포트 벡터가 여러 개일 수 있다.
① 다른 모형에 비해 속도가 빠르다.
46. 다차원 척도법에 대한 설명으로 옳지 않은 것은?
① 개체들 사이의 유사성, 비유사성을 측정하여 2차원 또는 3차원 공간상에 점으로 표현하여 개체들 사이의 집단화를 시각적으로 표현하는 분석 방법이다.
② 공분산 행렬을 사용하여 고윳값이 1보다 큰 주성분의 개수를 이용한다.
③ 스트레스 값이 0에 가까울수록 적합도가 좋다.
④ 유클리드 거리와 유사도를 이용하여 구한다.
② 공분산행렬을 사용하여 고윳값이 1보다 큰 주성분의 개수를 이용한다.
47. 다음 분석 변수 선택 방법이 설명하는 기법은?
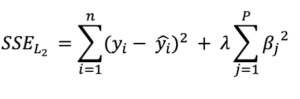
① 릿지(Ridge)
② 라쏘(Lasso)
③ 엘라스틱 넷(Elastic Net)
④ RFE(Recursive Feature Eliminnation)
48. 데이터 분석 절차로 가장 적합한 것은 무언인가?
① 문제 인식 → 자료 수집 → 연구 조사 → 자료 분석 → 모형화 → 분석 결과 공유
② 연구 조사 → 문제 인식 → 자료 수집 → 모형화 → 자료 분석 → 분석 결과 공유
③ 문제 인식 → 연구 조사 → 모형화 → 자료 수집 → 자료 분석 → 분석 결과 공유
④ 문제 인식 → 연구 조사 → 자료 수집 → 자료 분석 → 모형화 → 분석 결과 공유
④ 문제 인식 → 연구 조사 → 자료 수집 → 자료 분석 → 모형화 → 분석 결과 공유
49. 독립변수가 연속형이고 종속변수가 이산형일 때 사용하는 분석 모형은?
① 인공신경망 모델
② 로지스틱 회귀 분석
③ 회귀 분석
④ 의사결정나무
② 로지스틱 회귀 분석
50. 다음은 암 진단을 예측한 것과 실제 암 진단 결과를 혼동 행렬로 나타낸 것이다. 아래 표를 보고 TPR, FPR의 확률을 구계산하시오. ( 단, 결과가 음성이라는 뜻인 0을 Positive로 한다.)

① TPR: 9/10, FPR: 1/4
② TPR: 9/10, FPR: 1/48
③ TPR: 3/4, FPR: 1/48
④ TPR: 3/4, FPR: 1/4
③ TPR: 3/4, FPR: 1/48
51. 예측력이 약한 모형을 연결하여 강한 모형으로 만드는 기법으로 오분류된 데이터에 가중치를 두어 표본을 추출하는 앙상블 기법과 알고리즘은?
① 배깅 - AdaBoost
② 배깅 - 랜덤 포레스트
③ 부스팅 - 랜덤 포레스트
④ 부스팅 - GBM
④ 부스팅 - GBM
52. 사건 A, B가 있다. x가 발생했을 때, B가 일어날 확률인 P(B|x)를 구하는 공식으로 옳은 것은?
② 자료형이 범주형을 갖는 경우 사용하는 분석기법이다.
③ Y값은 0과 1 사이이다.
④ 대표적인 비지도 학습 알고리즘이다.
④ 대표적인 비지도 학습 알고리즘이다.
53. 전체 데이터 집합을 동일 크기로 갖는 K개의 부분 집합으로 나누고, 훈련 데이터와 평가 데이터로 나누는 기법은 무엇인가?
① K-Fold
② 홀드 아웃(Holdout)
③ Dropout
④ Cross Validation
① K-Fold
54. 다음 중 비지도 학습 알고리즘의 사례로 옳은 것은?
① 과거 데이터를 기준으로 날씨 예측
② 제품의 특성, 가격 등으로 판매량 예측
③ 페이스북 사진으로 사람을 분류
④ 부동산으로 지역별 집값을 예측
③ 페이스북 사진으로 사람을 분류
55. 다음에 이미지를 판별하기 위한 가장 적절한 분석법은 무엇인가?

① 군집
② 예측
③ 분류
④ 연관성
③ 분류
56. 학생들의 교복의 표준 치수를 정하기 위해 학생들의 팔길이, 키, 가슴둘레를 기준으로 할 때 어떤 방법이 가장 적절한 기법인가?
① 이상치
② 군집
③ 분류
④ 연관성
② 군집
57. 다음 중 시계열 모형이 아닌 것은?
① 백색 잡음
② 이항 분포
③ 자기 회귀
④ 이동평균
② 이항 분포
58. 비정형 데이터에 대한 설명으로 옳지 않은 것은?
① 텍스트는 문자 데이터로 저장한다.
② 오디오는 CMYK 형태로 저장한다.
③ 이미지는 RGB 방식으로 저장한다.
④ 비디오는 이미지 스트리밍으로 저장한다,
② 오디오는 CMYK 형태로 저장한다.
59. 랜덤 포레스트에 대한 설명으로 적절하지 않은 것은?
① 훈련을 통해 구성해놓은 다수의 나무들로부터 투표를 통해 분류 결과를 도출한다.
② 분류기를 여러 개 쓸수록 성능이 좋아진다.
③ 트리의 수가 많아지면 Overfit 된다.
④ 여러 개의 의사결정 트리가 모여서 랜덤 포레스트 구조가 된다.
④ 경사 하강법
60. K-Fold에 대한 설명으로 옳지 않은 것은?
① 데이터를 K개로 나눈다.
② 1개는 훈련 데이터, (K-1) 개는 검증 데이터로 사용한다.
③ K번 반복 수행한다.
④ 결과를 K에 다수결 또는 평균으로 계산한다.
② 1개는 훈련데이터, (K-1)개는 검증 데이터로 사용한다.
[4과목 빅데이터 결과 해석]
61. 다음 중 이상적인 분석 모형을 위해 Bias와 Variance는 어떻게 설정되어야 하는가?
① 높은 Bias, 높은 Variance가 있을 때
② 낮은 Bias, 높은 Variance가 있을 때
③ 낮은 Bias, 낮은 Variance가 있을 때
④ 높은 Bias, 낮은 Variance가 있을 때
③ 낮은 Bias, 낮은 Variance가 있을 때
62. 다음 중 초매개변수(Hyper Parameter)로 설정 가능한 것은?
① 편향(Variance)
② 기울기(Bias)
③ 서포트 벡터(Support Vector)
④ 은닉층(Hidden Layer) 수
④ 은닉층(Hidden Layer) 수
63. 다음 중 산점도(Scatter Plot)와 비슷한 시각화는 무엇인가?
① 파이 차트(Pie Chart)
② 버블 차트(Bubble Chart)
③ 히트맵(Heat Map)
④ 트리맵(Tree Map)
② 버블 차트(Bubble Chart)
64. 다음 중 분포 시각화의 유형으로, 설명 변수가 늘어날 때마다 축이 늘어나는 시각화 방법은 무엇인가?
① 플로팅 바 차트(Floating Bar Chart)
② 막대 차트(Bar Chart)
③ 스타 차트(Star Chart)
④ 히트맵(Heat Map)
③ 스타 차트(Star Chart)
65. 불균형 데이터 세트(Imbalanced Dataset)로 이진 분류 모형을 생성 시 불균형을 해소하기 위한 방법으로 옳지 않은 것은 무엇인가?
① 다수 클래스의 데이터를 일부만 선택하여 데이터의 비율을 맞춘다.
② 임곗값을 데이터가 적은 쪽으로 이동시킨다.
③ 서로 다른 여러 가지 모형들의 예측 결과를 종합한다.
④ 소수 클래스의 데이터를 복제 또는 생성하여 데이터의 비율을 맞춘다.
② 임곗값을 데이터가 적은 쪽으로 이동시킨다.
해설
임곗값을 데이터가 많은 쪽으로 이동시킨다.
66. 다음 중 ROC 커브에 대한 설명으로 적합하지 않은 것은?
① x축은 특이도를 의미한다.
② y축은 민감도를 의미한다.
③ AUC(Area Under ROC) 1.0에 가까울수록 분석 모형 성능이 우수하다.
④ AUC(Area Under ROC) 0.5, 일 경우 랜덤 선택에 가까운 성능을 보인다.
① x축은 특이도를 의미한다.
해설
x축은 거짓 긍정률이다.
y축은 민감도=재현율=참 긍정률이다,
67. 다음 혼동 행렬(Cofusion Matrix)에서 참이 0이고 거짓이 1일 때, Specificity와 Precision은 무엇인가?
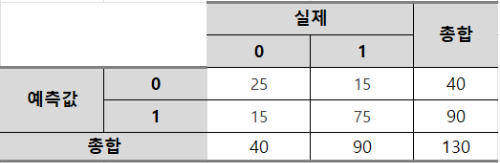
① Specificity: 5/8, Precision: 5/8
② Specificity: 5/8, Precision: 5/6
③ Specificity: 5/6, Precision: 5/6
④ Specificity: 5/6, Precision: 5/8
④ Specificity: 5/6, Precision: 5/8
68. 다음 중 매개변수(Parameter), 초매개변수(Hyper Parameter)에 대한 것으로 적절하지 않은 것은?
① 매개변수는 사람에 의해 수작업으로 설정한다.
② 매개변수는 측정되거나 데이터로부터 학습된다.
③ 초매개변수는 학습을 위해 임의로 설정하는 값이다.
④ 초매개변수의 종류에는 숨은 은닉층, 학습률 등이 있다.
① 매개변수는 사람에 의해 수작업으로 설정한다.
69. 다음 중 k-평균 군집(k-meas clustering) 알고리즘을 통해 K값을 구하는 기법은 무엇인가?
① K-Centroid 기법
② 최장 연결법
③ 엘보우 기법
④ 역전파 알고리즘
③ 엘보우 기법
70. 다음 중 F-Score에 들어가는 지표는?
① TP Rate, FP Rate
② Accuracy, Sensitivity
③ Specificity, Error Rate
④ Precision, Recall
④ Precision, Recall
71. 종속변수가 범주형이고 독립변수가 수치형 변수 여러 개로 이루어진 변수 간의 관계를 분석하기 위해 이용할 수 있는 알고리즘으로 올바른 것은?
① 로지스틱 회귀 분석(Logistic Regression Analysis)
② k-평균 군집(k-means clustering)
③ 주성분 분석(Principal Component Analysis)
④ DBSCAN
① 로지스틱 회귀 분석(Logistic Regression Analysis)
72. 다음 중 적합도 검정 기법으로 올바르지 않은 것은?
① 적합도 검정에서 자유도는 (범주의 수) +1이다.
② 적합도 검정은 카이제곱 검정 기법의 유형에 속한다.
③ 적합도 검정의 자료를 구분하는 범주가 상호 배타적이어야 한다.
④ 적합도 검정은 표본 집단의 분포가 주어진 특정 이론을 따르고 있는지를 검정하는 기법이다.
① 적합도 검정에서 자유도는 (범주의 수) +1이다.
73. 다음 중 인포그래픽에 대한 설명으로 옳지 않은 것은?
① 도표나 글에 비해 시각적 기법을 사용하여 기억에 오랫동안 남는다.
② 히스토그램의 y축을 평균으로도 나타낼 수 있다.
③ 계급수를 잘 정해야 정확한 분포 파악이 가능하다.
④ 누적확률분포표는 누적확률밀도함수와 비슷한 형태를 보인다.
③ 계급수를 잘 정해야 정확한 분포 파악이 가능하다.
74. 과대적합일 때 대응방법이 아닌 것은?
① Regularization
② Batch Nomalization
③ Drop-out
④ Max Pooling
④ Max Pooling
75. 회귀분석 log(odds) = a + bx 설명으로 가장 거리가 먼것은?
① a,b 둘다 0이면 y확률 0이다.
② Log 연산을 통해 0에서 1사이의 Logit을 획득한다.
③ 오즈(Odds)는 클래스 0에 속하는 확률에 대한 클래스 1에 속하는 확률의 비이다.
④ 승산비(Odd Ratio)사건이 발생한 확률과 발생하지 않을 확률 간의 비율이다.
① a,b 둘다 0이면 y확률 0이다.
76. 혼돈행렬에서의 FN 해석에 대한 것으로 알맞은 것은?
① 예측값 False 실제값 False
② 예측값 False 실제값 True
③ 예측값 True 실제값 False
④ 예측값 True 실제값 True
② 예측값 False 실제값 True
77. 다음 중 데이터 분석 결과 활용에 대한 설명으로 옳지 않은 것은?
① 분석 모형 최종 평가 시에는 학습할 때 사용하지 않았던 데이터를 사용한다.
② 분석 모형 개발과 피드백 적용 과정을 반복하는 것은 지양한다.
③ 정확도, 재현율 등의 평가지표를 분석 모형 성능 지표로 활용한다,
④ 분석 결과는 비즈니스 업무 담당자, 시스템 엔지니어 등 관련 이누언들에게 모두 공유되어야 한다.
② 분석 모형 개발과 피드백 적용 과정을 반복하는 것은 지양한다.
78. 보고서 작성시 방법으로 가장 거리가 먼 것은?
① 전문용어를 많이 사용한다.
② 쉽게 이해할 수 있도록 작성한다.
③ 비즈니스에 사용할 수 있도록 한다.
④ 보고서를 통해 성과 기준과 기여도를 표현할 수 있도록 한다.
① 전문용어를 많이 사용한다.
79. 회귀계수의 유의성 검정? (유사한 유형)
어느 중하교에서 1학년 학생들의 키의 차이가 2학년이 되면 더 커질 것이라고 예상된다. 1학년에서 6명을 뽑고, 2학년에서 8명을 뽑아서 각각의 성적의 분산을 조사해 봤더니, 1학년의 분산은 10.0이었고 2학년의 분산은 50.0이었다. 두모집단의 분산은 같다고 볼 수 있을까?
a=0.05에서 검정해보자.
① F통계량, p-value < 유의수준, 귀무가설 채택
② F통계량, p-value < 유의수준, 귀무가설 기각
③ 카이제곱, p-value < 유의수준, 귀무가설 채택
④ 카이제곱, p-value < 유의수준, 귀무가설 기각
② F통계량, p-value < 유의수준, 귀무가설 기각
80. 회귀 모형의 잔차를 분석한 결과가 아래와 같이 나타날 때, 이에 대한 설명으로 옳은 것은?
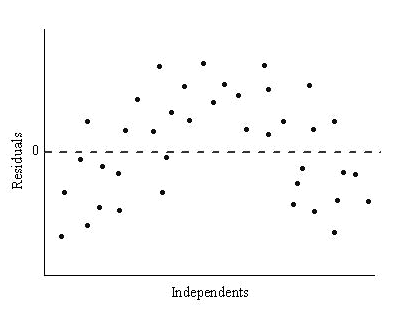
① 잔차가 등분산 가정을 만족한다.
② 종속변수를 log로 변환하여 문제를 해결한다.
③ 독립변수 중 하나를 제곱하여 문제를 해결한다.
④ 잔차가 정규분포를 따르지 않는다.
② 종속변수를 log로 변환하여 문제를 해결한다.
'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사 필기] 변수 변환 방법과 기출문제 (0) | 2022.10.01 |
|---|---|
| [빅데이터분석기사 필기] 서포트 벡터 머신(SVM)의 개념과 기출문제 (0) | 2022.10.01 |
| [빅데이터분석기사 필기] 하둡 에코시스템의 다양한 기술과 기출문제 (1) | 2022.09.30 |
| [빅데이터분석기사 필기] 데이터 저장기술 종류와 기출문제 (0) | 2022.09.29 |
| [빅데이터분석기사 필기] 데이터 수집 개념 및 기출문제 (0) | 2022.09.29 |