728x90
반응형
이전글 보러가기
[빅데이터분석기사 필기] 2과목 빅데이터탐색 요약정리
이전글 보러가기 [빅데이터분석기사 필기] 1과목 빅데이터분석기획 요약정리 ⭐: 키워드 ⭐⭐:기출문제 유형 ⭐⭐⭐:출제 多 ① 빅데이터의 이해 ⭐ DIKW피라미드 Data ➡️ Information ➡️ Knowledge
ohaengsa.tistory.com
① 분석모형설계
⭐ 분석모형선정
- 분석목적에 부합하고 수집된 데이터의 변수들을 고려하여 적합한 빅데이터 분석 모형을 선정한다.
- 현상에서 패턴을 발견하는 것은 탐색적 데이터 분석이며 현상에서 인과적인 결론을 도출하는 것은 통계적 추천, 현상을 예측하는 것은 기계학습(머신러닝)이다.
- 통계, 데이터 마이닝, 머신러닝 기반 분석 모델 기법을 고려하여 적합한 빅데이터 분석 모델을 선정한다.
⭐ 통계기반 분석 모형
- 불확실한 상황에서 객관적인 의사결정을 수행하기 위해 데이터를 수집하고, 처리, 분류, 분석 및 해석하는 일련의 체계를 통계분석이라고 한다.
- 기술통계, 상관분석, 회귀 분석, 분산분석, 주성분 분석, 판별분석
⭐⭐ 데이터마이닝 기반 분석 모형 선정
- 데이터마이닝 : 대용량 데이터로부터 데이터 내에 존재하는 패턴, 관계 혹은 규칙 등을 탐색하고 통계적인 기법들을 활용하여 모델화하며 이를 통해 데이터 분석 및 유용한 정보, 지식등을 추출하는 과정이다.
- 데이터 마이닝 기반 분석 모델은 분류, 예측, 군집화, 연관규칙이 있다.
- 분류 모델
- 범주형 변수 혹은 이산형 변수 등의 범주를 예측하는 거승로 다수의 속성 혹은 변수를 가지는 객체들을 사전에 정해진 그룹이나 범주 중의 하나로 분류하는 모델이다.
- 학습한 내용을 활용해서 숫자 이미지 분류를 할 수 있다.
- 통계적 기법, 트리 기반 기법, 최적화 기법, 기계학습 모델
- 예측 모델
- 예측 모델은 범주형 및 수치형 등의 과거 데이터로부터 특성을 분석하여 다른 데이터의결괏값을 예측하는 기법이다.
- 회귀 분석, 의사결정나무, 인공신경망 모델, 시계열 분석 등
- 군집화 모델
- 군집화는 이질적인 집단을 몇 개의 동질적인 소집단으로 세분화하는 작업이다.
- 각 개제에 대해 관측된 여러 개의변숫값에서 유사한 성격을 갖는 몇 개의 군집으로 집단화하여 군집들 사이의 관계를 분석하는 다변량 분석 기법이다.
- 학생들 교복의 표준 치수를 정하기 위해 학생들의 팔길이, 키. 가슴둘레를 기준으로 묶을 수 있다.
- 계층적 방법, 비계층적 방법이 있다.
- 연관규칙 모델
- 데이터에 숨어 있으면서 동시에 발생하는 사건 혹은 항목 간의 규칙을 수치화하는 기법이다.
- 연관규칙 모델을 사용하는 연관 분석은 장바구니 분석이라고도 불리며 주로 마케팅에서 활용된다.
⭐⭐ 머신러닝 기반 분석 모형 선정
- 머신러닝 기반의 데이터 분석 기법은 일반적으로 목적변수 존재 여부 등에 따라 지도학습과 비지도 학습, 강화학습, 준지도 학습으로 구분한다.
- 지도 학습
- 정답인 레이블이 포함되어 있는 학습데이터를 통해 컴퓨터를 학습시키는 방법이다.
- 설명변수와 목적변수 간의 관계성을 표현해내거나 미래 관측을 예측해내는 것에 초점이 있으며 주로 인식, 분류, 진단, 예측 등의 문제 해결에 적합하다.
- 로지스틱 회귀, 인공신경망 분석, 의사결정나무, 서포트 벡터 머신, 랜덤 포레스트, 감성 분석
- 비지도 학습
- 입력데이터에 대한 정답인 레이블이 없는 상태에서 훈련데이터를 통해 학습시키는 방법
- 군집분석, 연관 관계분석, 딥러닝
- 강화학습 : 선택 가능한 행동 중 보상을 최대화하는 행동 혹은 행동 순서를 선택하는 학습 방법이다.
- 준지도 학습 : 정답인 레이블이 포함되어 있는 훈련데이터와 레이블이 없는 훈련 데이터를 모두 훈련에 사용하는 학습 방법이다.
⭐⭐ 변수에 따른 분석 기법 선정
- 변수의 개수에 따른 분석 기법 : 단일변수 분석, 이변수 분석, 다변수 분석
- 독립변수와 종속변수가 주어진 경우 분석 기법 : 독립변수와 종속변수의 데이터 유형에 따라서 다양한 통계적 혹은 데이터 마이닝 기반 분석 기법들의 분류가 가능하다.
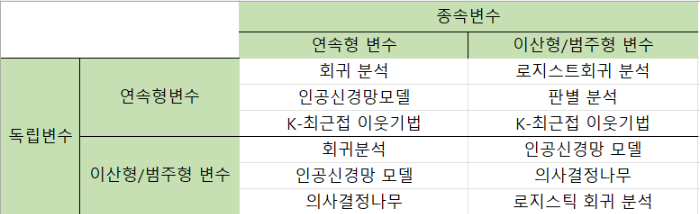
⭐ 분석 기법 선정 고려사항
- 분석 모형을 구축하는 목적과 입력되는 데이터, 변수의 해석 가능 여부에 따라 기법을 선택한다.
- 단일 모형을 선택하거나 다수의 모형을 조합한 앙상블 기법을 선택한다.
⭐ 분석 모형 활용 사례
- 연관규칙학습, 분류 분석, 유전자 알고리즘, 기계학습, 회귀분석, 감성 분석, 소셜네트워크 분석
⭐⭐ 분석 모형 정의 [기출]
- 분석 모형을 선정하고 모형에 적합한 변수를 선택하여 모형의 사양을 작성하는 기법이다.
- 선택한 모델에 가장 적합한 변수를 선택하기 위해 매개 변수와 초매개변수를 선정한다.
- 매개변수
- 사람에 의해 수작업으로 측정되지 않는다.
- 측정되거나 데이터로부터 학습된다.
- 모델 내부에서 확인이 가능한 변수로 데이터를 통해서 산출이 가능한 값
- 초매개변수
- 학습을 위해 임의로 설정하는 값이다.
- 학습률, 의사결정나무의 깊이, 신경망에서 은닉층의 개수, 서포트 벡터 머신에서의 코스트값인 C, KNN에서의 K의 개수
- 최적화 알고리즘 : Manulal search, 랜덤서치, 그리드서치, 베이지안 최적화
- 분석 대상인 데이터에 비해 모델이 너무 간단하면 과소 적합이 발생하고, 모델을 너무 복잡하게 선택하면 과대 적합이 발생하므로 적절한 모델을 사용한다.
⭐ 분석모형 구축 절차
- 요건 정의 ➡️ 모델링 ➡️ 검증 및 테스트 ➡️ 적용
- 요건정의 : 기획단계의 분석과제 정의를 통해 도추된 내용을 요건 정의로 구체화하는 과정이다.
- 모델링 : 요건 정의에 따라 상세 분석 기법을 적용해 모델을 개발하는 과정이다.
- 검증 및 평가 : 분석 데이터를 훈련과 평가 데이터로 분리한 다음 분석데이터를 이용해 자체 검증 후 실제 평가에서는 신규 데이터 모델을 적용해 결과를 도출하는 과정이다.
- 적용 : 분석결과를 업무 프로세스에 완전히 통합해 실제 일, 주, 월 단위로 운영하는 단계이다.
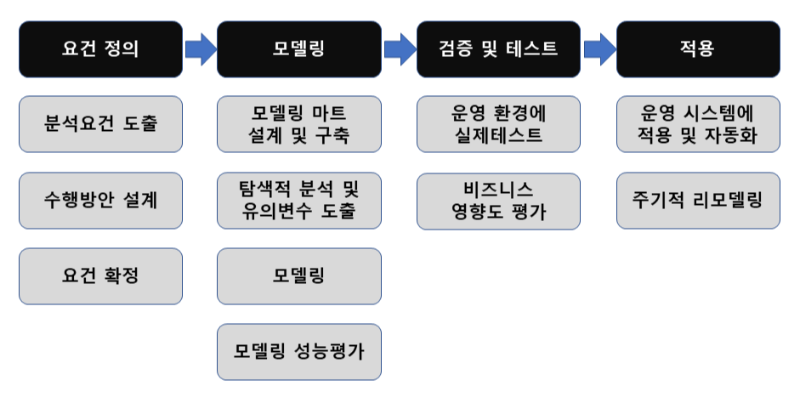
⭐ 분석 도구 선정
- 빅데이터 분석을 위한 대표적인 도구로는 R과 파이썬이 있다.
- R : S언어를 기반으로 만들어진 오픈 소스 프로그래밍언어이다.
- 파이썬 : R과 거의 같은 작업 수행이 가능한 C언어 기반의 오픈 소스 프로그래밍 언어이다.
⭐⭐ 데이터분할
- 데이터를 훈련 데이터, 검증데이터, 평가 데이터로 분할하는 작업이다.
- 과대 적합의 문제를 예방하여 2종 오류 잘못인 귀무가설을 채택하는 오류를 방지하는데 목적이 있다.
- 훈련데이터와 검증 데이터는 학습 과정에서 사용하며 평가데이터는 학습 과정에 사용되지 않고 오로지 모형의 평가를 위한 과정에만 사용된다.
- 데이터 분할 시 학습데이터와 테스트 데이터는 곂쳐서는 안된다.
- 검증데이터와 테스트 데이터는 일치할 수 있다.
다음글 보러가기
빅데이터분석기사 3과목 빅데이터모델링 요점정리 ②
[빅데이터 분석기사 필기] 3과목 빅데이터모델링 요점정리 ②
② 분석 기법 적용 ⭐ 회귀분석 독립변수와 종속변수 간에 선형적인관계를 도출해서 하나 이사으이 독립변수들이 종속변수에 미치는 영향을 분석하고 독립변수를 통해 종속변수를 예측하는 분
ohaengsa.tistory.com
728x90
반응형
'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사 필기] 주성분분석(PCA) 개념 및 기출문제 (1) | 2022.09.27 |
|---|---|
| [빅데이터 분석기사 필기] 3과목 빅데이터모델링 요점정리 ② (1) | 2022.09.27 |
| [빅데이터분석기사 필기] 한번에 합격하는 공부법 (0) | 2022.09.17 |
| [빅데이터분석기사 필기] 2과목 빅데이터탐색 요약정리 (4) | 2022.09.14 |
| [빅데이터분석기사 필기] 1과목 빅데이터분석기획 요약정리 (1) | 2022.09.14 |