728x90
반응형
이전글 보러가기
[빅데이터 분석기사 필기] 3과목 빅데이터모델링 요점정리 ①
[빅데이터 분석기사 필기] 3과목 빅데이터모델링 요점정리 ①
이전글 보러가기 [빅데이터분석기사 필기] 2과목 빅데이터탐색 요약정리 이전글 보러가기 [빅데이터분석기사 필기] 1과목 빅데이터분석기획 요약정리 ⭐: 키워드 ⭐⭐:기출문제 유형 ⭐⭐⭐:출
ohaengsa.tistory.com
② 분석 기법 적용
⭐⭐ 회귀분석
- 독립변수와 종속변수 간에 선형적인 관계를 도출해서 하나 이상의 독립변수들이 종속변수에 미치는 영향을 분석하고 독립변수를 통해 종속변수를 예측하는 분석 기법이다.
- 변수들 사이의 인과관계를 밝히고 모형을 적합하여 관심 있는 변수를 예측하거나 추론하기 위한 분석 방법이다.
- 유형 : 단순선형 회귀, 다중선형회귀, 다항 회귀, 곡선 회귀, 로지스틱 회귀, 비선형회귀
⭐⭐ 회귀 모형의 가정 [기출]
- 선형성, 독립성, 등분상성, 비상관성, 정상성의 5가지 가정을 만족시켜야한다.
- 선형성: 독립변수와 종속변수가 선형적이어야 한다는 특성
- 독립성 : 잔차와 독립변수의 값이 서로 독립적이어야 한다는 특성
- 정규성 : 잔차항이 정규분포의 형태를 이뤄야한다.
- 등분산성 : 잔차의 분산이 동일한 분산을 갖는다.
- 비상관성 : 잔차들끼리 상관이 없어야한다.
⭐⭐ 회귀 모형 검증 [기출]
- 회귀모형이 통계적으로 유의미한가?
- F-통계량을 통해 확인한다.
- 유의수준 5%하에서 F-통계량의 p-값이 0.05보다 작으면 회귀식은 통계적으로 유의미하다고 볼 수 있다.
- 회귀계수들이 유의미한가? : t-통계량을 통해 각 독립변수가 종속변수에 미치는 영향을 파악한다.
- 회귀 모형이 얼마나 설명력을 갖는가? : 결정계수로 판단한다.
- 회귀 모형이 데이터를 잘 적합하고 있는가? : 잔차통계량을 확인한다.
- 데이터가 가정을 만족시키는가? : 선형성, 독립성, 등분산성, 비상관성, 정상성 가정을 만족시켜야 한다.
⭐⭐ 잔차도(Residual Plot) [기출]
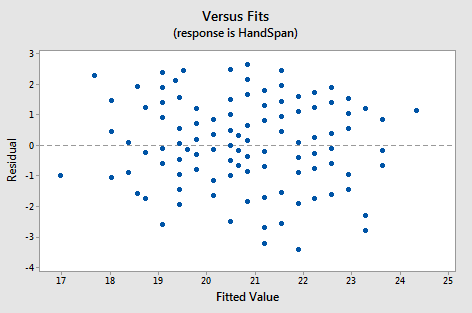
- 모든 값들에 대하여 잔차의 분산이 동일하다는 가정이 전제되어야한다.
- 가중최소 자승법을 사용하거나 종속변수를 log로 변환하여 문제를 해결한다.
⭐⭐ 로지스틱 회귀 분석 [기출]
- 독립변수가 수치형이고 종속변수가 범주형인 경우 적용되는 회귀 분석 모형이다.
- 모형의 적합을 통해 추정된 확률을 사후 확률로도 부른다.
- 종속변수가 범주형(이항형)인 경우 로지스틱 회귀 분석을 사용해야한다.
- 결과값이 항상 [0,1] 사이에 있도록 한다.
- 오즈 : 특정사건이 발생활 확률과 그 사건이 발생하지 않을 확률의 비다.
- 로짓 변환 : 오즈에 로그를 취한 함수로서 입력값의 범위가 [0,1]일 때 출력값의 범위를 (-무한대, 무한대)로 조정한다.
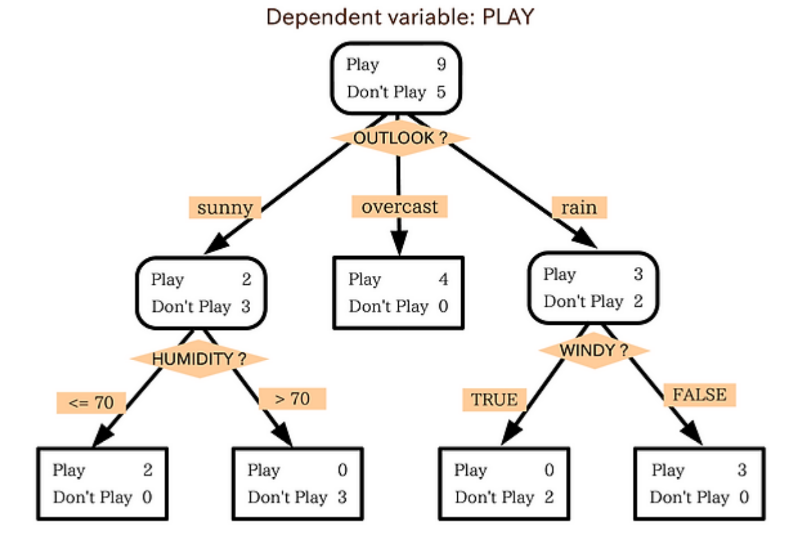
⭐⭐ 의사결정나무 [기출]
- 의사결정 규칙을 나무구조로 나타내어 전체 자료를 몇개의 소집단으로 분류하거나 예측을 수행하는 분석방법이다.
- 변수를 하나 정해 한계치를 설정한다.
- 범주형(이산형)과 수치형(연속성)변수를 모두 사용할 수 있다.
- 의사결정 나무성장 ➡️ 가지치기 ➡️ 타당성 평가 ➡️ 해석 및 예측
- 목표변수가 이산형인 경우에는 분류나무로 구분하며 카이제곱 통계량, 지니함수, 엔트로피 지수를 사용한다.
- 목표변수가 연속형인 경우에는 회귀나무로 구분되며 F-통계량, 분산의 감소량을 사용한다.
- 정지규칙은 더 이상 분리가 일어나지 않고 현재의 마디가 끝마디가 되도록 하는 규칙이다.
- 정지규칙을 만족하면 의사결정나무 성장을 중단한다.
- 정지기준은 의사결정나무의 깊이를 지정, 끝마디의 레코드 수의 최소개수를 지정한다.
- 의사결정나무 알고리즘 : CHAID, QUEST, CART, C4.5/C5.0
- CHAID : 카이제곱 통계량, F-통계량 사용
- QUEST : 카이제곱 통계량, F-통계량 사용
- CART : 지니지수, 분산의 감소량 사용
- C4.5/C5.0 : 엔트로피 지수 사용
- 나무구조에 의해 모델이 표현되기 때문에 해석에 용이한 편이다.
⭐ 인공신경망
- 사람 두뇌의 신경세포인 뉴런이 전기신호를 전달하는 모습을 모방한 기계학습 모델이다.
- 입력값을 받아서 출력값을 만들기 위해 활성화 함수를 사용한다.
- 가중치를 알아내는 것이 목적이다.
- 인공신경망을 이용하면 분류 및 예측을 할 수 있다.
- 입력층, 은닉층, 출력층의 3개 층으로 구성된다.
- 미니배치 학습 ➡️ 기울기 산출 ➡️ 매개변수 갱신 ➡️ 반복
⭐퍼셉트런
- 인간의 신경망에 있는 뉴런의 모델을 모방하여 입력층, 출력층으로 구성한 인공신경망 모델이다.
- 입력값, 가중치, 순 입력함수, 활성화 함수, 예측값으로 되어 있다.
- XOR선형 분리를 할 수 없는 문제점이 있다.
⭐ 다층 퍼셉트론
- 입력층과 출력층 사이에 하나 이상의 은닉층을 두어 비선형적으로 분리되는 데이터에 대해 학습이 가능한 퍼셉트론이다.
- 입력층, 은닉층, 출력층으로 구성하고 역전파 알고리즘을 통해 다층으로 만들어지 퍼센트론의 학습이 가능하다.
- 활성화 함수로 시그모이드 함수를 사용하였다.
- 문제점으로는 과대적합, 기울기 소실이 있다.
⭐ 과대 적합
- 학습 데이터가 부족하여 학습 데이터에는 잘 동작하지만 실제 데이터에는 예측을 못하는 문제점이 존재한다.
- 학습 데이터 부족으로 인한 과적합은 빅데이터 시대가 열리면서 데이터 확보가 용이해져 해결이 되었다.
⭐기울기소실
- 역전파 알고리즘은 학습하는 과정에서 출력층 ➡️은닉층 ➡️입력층➡️ 방향으로 편미분을 진행한다.
- 활성화 함수인 시그모이드 함수는 편미분이 진행할수록 0으로 근접해져 기울기가 소실되는 문제점이 발생한다.
- ReLU함수를 사용하여 문제를 해결한다.
⭐활성화함수
- 입력함수로부터 전달받은 값을 출력갑승로 변환해주는 함수이다.
- 가중치 값을 학습할 때 에러가 적게나도록 돕는 역할을 한다.
- 비선형 함수를 사용해야 다수의 은닉층을 추가할 수 있다.
- 종류 : sigmoid, ReLU, ELU, Leaky ReLU, Maxout, tanh, softmax
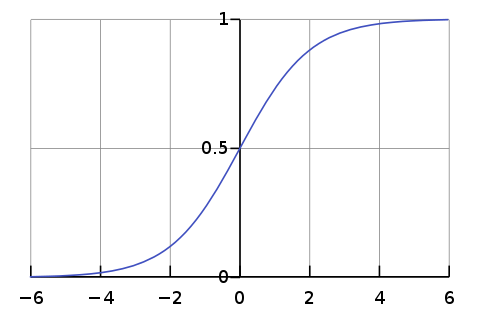
⭐ 시그모이드 함수(Sigmoid)
- 연속형 0~1, Logistic함수라 불리기도한다.
- 선형적인 다중퍼셉트론에서 비선형 값을 얻기 위해 사용한다.
- 기울기 소실의 원인이다.
- x=0에서 기울기가 최대이고 x가 크거나 작을 때 기울기가 0에 가까워진다.
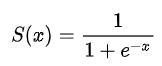
⭐tanh
- sigmoin 중심값을 0으로 이동한것이다.
⭐ReLU
- 학습이 빠르고 미분값이 0,1 두 개 중 하나이기 때문에 자원 소모가 적언 일반적으로 쓰는 함수중 한가지이다.
- 기울기 소실 문제를 해결하였다.
- x<0인 경우 Dying ReLU현상이 발생한다.
⭐Leaky ReLU
- 0보다 작은 입력에 대해 기울기를 주어 Dying ReLU 현상을 해결했다.
⭐소프트맥스(Softmax)
- 세개 이상의 다중 클래스 분류에 사용되는 활성화 함수이다.
- 지수함수를 적용하여 작은 값 차이도 구별 가능한 차이로 커진다.
- 시그모이드 함수와 같이 출력층에서 주로 사용한다.
- 출력값의 총합은 1이된다.
⭐ 순전파
- 입력층에서 출력층까지 정보가 전달되는 과정이다.
- 입력값과 가중치를 사용하여 예측값을 구한다.
- 은닉층에서는 가중치가 반영된 입력값의 합계를 활성화 함수로 계싼하고 결과값을 출력층으로 전달한다.
⭐ 손실함수(비용함수)
- 실젯값과 예측값의 차이(오차)를 비교하는 지표이다,
- 겂아 낮을수록 학습이 잘된것이라고 볼 수 있고 정답과 알고리즘 출력을 비교할 때 사용한다.
- 평균 제곱 에러 : 출력결과와 데이터 차이 제곱의 평균으로 정답과 오답의 모든 확률을 고려한다.
- 교차 엔트로피 오차 : 실제 정답의 확률만을 고려한 손실함수이다.
⭐경사하강법
- 기울기를 낮은 쪽으로 계쏙 이동시켜서 최적의 매개변수를 찾는 기법이다.
- 기울기를 낮은 쪽으로 계속 이동시켜 극값에 이를 때까지 반복시키는 기법이다.
- 비용 함수의 기울기의 최소값을 찾아내는 머신러닝 알고리즘이다.
⭐오차역전파
- 계산 결과의 정답의 오차를 구하고 오차와 관련된 값들의 가중치를 수정하여 오차가 작아지는 방향으로 일정 횟수를 반복해서 수정하는 방법이다.
⭐⭐ 서포트벡터머신
- 지도학습기반의 이진 선형 분류 모델이다.
- 다른 모형보다 과대적합에 강하다.
- 비선형 모델 분류가 가능하다.
- 서포트 벡터가 여러 개일 수 있다.
- 다른 모형에 디해 속도가 느리다.
- 정확성이 뛰어나다.
⭐연관성 분석
- 데이터 내부에 존재하는 항목 간의 상호 관계 혹은 종속 관계를 찾아내는 분석 기법이다.
- 장바구니 분석, 서열 분석이라고도 한다.
- 측정지표로는 지지도, 신뢰도, 향상도가 있다.
- 아프리오리(Apriori) 알고리즘 : 가능한 모든 경우의 수를 탐색하는 방식을 개선하기 위하여 데이터들의 발생빈도가 높은 것을 찾는 알고리즘이다.
- FP-Growth 알고리즘 : 아프리오 알고리즘을 개선한 알고리즘으로 FP-Tree라는 구조를 통해 최소 지지도를 만족하는 빈발 아이템 집합을 추출하는 알고리즘이다.
⭐군집분석
- 관측된 여러 개의 변숫값들로부터 유사성에만 기초하여 n개의 군집으로 집단화하여 집단의 특성을 분석하는 다변량 분석 기법이다.
- 군집 분석의 목적은 레이블이 없는 데이터 세트의 요약 정보를 추출하고, 요약 정보를 통해 전체 데이터 세트가 가지고 있는 특징을 발견하는 것이다.
- 비지도 학습이다.
- 기법 : 계층적 군집, k-평균 군집, 자기조직화지도(SOM)
- 활용 : 세분화, 이상탐지, 분리. 시장과 고객 차별화, 패턴인식, 생물연구, 공간데이터 분석, 웹문서 분류 등
⭐⭐연속형 변수 거리
- 유클리드 거리 : 두점간차를 제곱하여 모두 더한 값의 양의 제곱근
- 맨하탄 거리 : 두점 간 차의 절댓값을 합한 값
- 민코프스키 거리
- m차원 민코프스키 공간에서의 거리
- m=1일때맨하탄 거리와 같음
- m=2일때 유클리드 거리와 같음
- 표준화 거리 : 변수의 측정단위를 표준화한 거리
- 마할라노비스 거리 : 변수의 표준화와 함께 변수 간의 상관성을 동시에 고려한 통계적 거리
⭐명목형 변수 거리
- 단순일치계수 : 전체 속성 중에서 일치하는 속성의 비율
- 자카드 계수
- 두집합 사이의 유사도를 측정하는 방법
- 0과 1사이의 값을 가지며 두 집합이 동일하면 1의값, 공통의 원소가 하나도 없으면 0의 값을 가짐
⭐순서형 변수 거리
- 순위상관계수 : 값에 순위를 매겨 그 순위에 대해 상관계쑤를 구하는 방법이다.
⭐계층적 군집
- 유사한 개체를 군집화하는 과정을 반복하여 군집을 형성하는 방법이다.
- 병합적 방법
- 작은 군집으로부터 시작하여 군집을 병합하는 방법
- 거리가 가까우면 유사성이 높음
- 분할적 방법 : 큰군집으로부터 출발하여 군집을 분리해 나가는 방법
- 거리측정 방법 : 최단연결법, 최장연결법, 중심연결법, 평균연결볍, 와드연결법
⭐계통도
- 군집의 결과는 계통도 또는 덴드로그램의 형태로 결과가 주어지며 각 개체는 하나의 군집에만 속하게 된다.
- 항목 간의 거리, 군집간의 거리를 알수 있고 군집내 항목간 유사정도를 파악함으로써 군집의 견고성을 해석할 수 있다.
⭐비계층적 군집 분석(k-평균 군집 알고리즘)
- 주어진 데이터를 k개의 군집으로 묶는 알고리즘으로 k개만큼 군집수를 초깃값으로 지정하고, 각 개체를 가까운 초깃값에 할당하여 군집을 형성하고 각 군집의 평균을 재계싼하여 초깃값을 갱신하는 과정을 반복하여 k개의 최종군집을 형성한다.
- k개 객체 선택 할당 중심 갱신 반복
- k-평균 군집은 이상값에 민감하게 반응하는 단점이 존재한다.
- 단점을 보완하는 방법으로는 k-중앙값 군집을 사용하거나 이상값을 미리 제거할 수도 있다.
⭐k-평균 군집 k값 선정 기법 [기출]
- 엘보우 기법 : 기울기가 완만한 부분에 해당하는 클러스터를 선택하는 기법
- 실루엣 기법
- 각군집 간의 거리가 얼마나 분리되어 있는지를 나타내는 기법
- 실루엣 계수는 1에 가까울 수록 군집간 거리가 멀어서 최적화가 잘 되어 있다고 할 수 있고 0에 가까울수록 군집간 거리가 가까워서 최적화가 잘 안되어 있다고 할 수 있음
- 덴드로그램 : 계층적 군집 분석의 덴드로그래 시각화를 이용하여 군집의 개수 결정
⭐비계층적 군집 분석(혼합분포군집)
- 혼합 분포 군집 : 데이터가k개의 모수적 모형의 가중합으로 표현되는 모집단 모형으로부터 나왔다는 가정하에서 자료로부터 모수와 가중치를 추정하는 방법이다.
- 가우시안 혼합 모델 : 전체 데이터의 확률분포가 k개의 가우시안 분포의 선형 결합으로 이뤄졌음을 가정하고 각 분포에 속할 확률이 높은 데이터 간의 군집을 형성하는 방법이다.
- EM알고리즘 : 관측되지 않은 잠재변수에 의존하는 확률모델에서 최대 가능도나 최대 사후 확률을 갖는 모수의 추정값을 찾는 반복적인 알고리즘이다.
⭐비계층적 군집 분석 - DBSCAN알고리즘
- 개체들의 밀도계산을 기반으로 밀접하게 분포된 개체들끼리 그룹핑하는 군집 분석 알고리즘이다.
⭐비계층적 군집 분석(SOM알고리즘)
- 대뇌피질과 시각피질의 학습 과정을 기반으로 모델화한 인공신경망으로 자율 학습 방법에 의한 클러스터링 방법을 적용한 알고리즘이다.
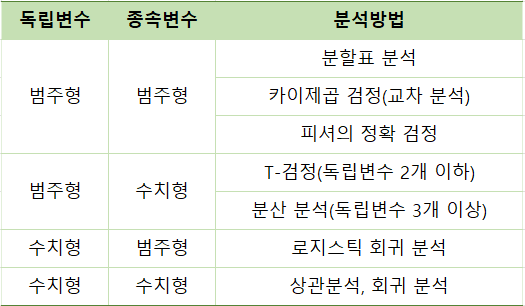
⭐ 범주형 자료 분석
- 독립변수와 종속변수가 모두 범주형 데이터이거나 둘 중 하나가 범주형 데이터일 때 사용하는 분석이다.
- 각 집단간의 비율 차이를 비교하기 위해 주로 사용된다.
- 독립변수와 종속변수의 척도에 따라 분석 기법이 다르다.
- 분할표 분석, 카이제곱 검정
728x90
반응형
'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사 필기] 시계열분석 개념 및 기출문제 (0) | 2022.09.27 |
|---|---|
| [빅데이터분석기사 필기] 주성분분석(PCA) 개념 및 기출문제 (1) | 2022.09.27 |
| [빅데이터 분석기사 필기] 3과목 빅데이터모델링 요점정리 ① (0) | 2022.09.23 |
| [빅데이터분석기사 필기] 한번에 합격하는 공부법 (0) | 2022.09.17 |
| [빅데이터분석기사 필기] 2과목 빅데이터탐색 요약정리 (4) | 2022.09.14 |